ChatGPTを使用する
AUTOROでは、ChatWithGPTアクションを用意しています。
このアクションに命令文(プロンプト)を入力すると、ChatGPTが返答します。
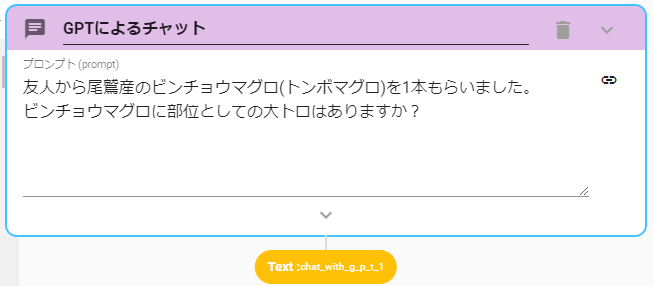

※2023-05-15現在、使用されているモデルはOpenAIのGPT-3.5-turboモデルとなります。
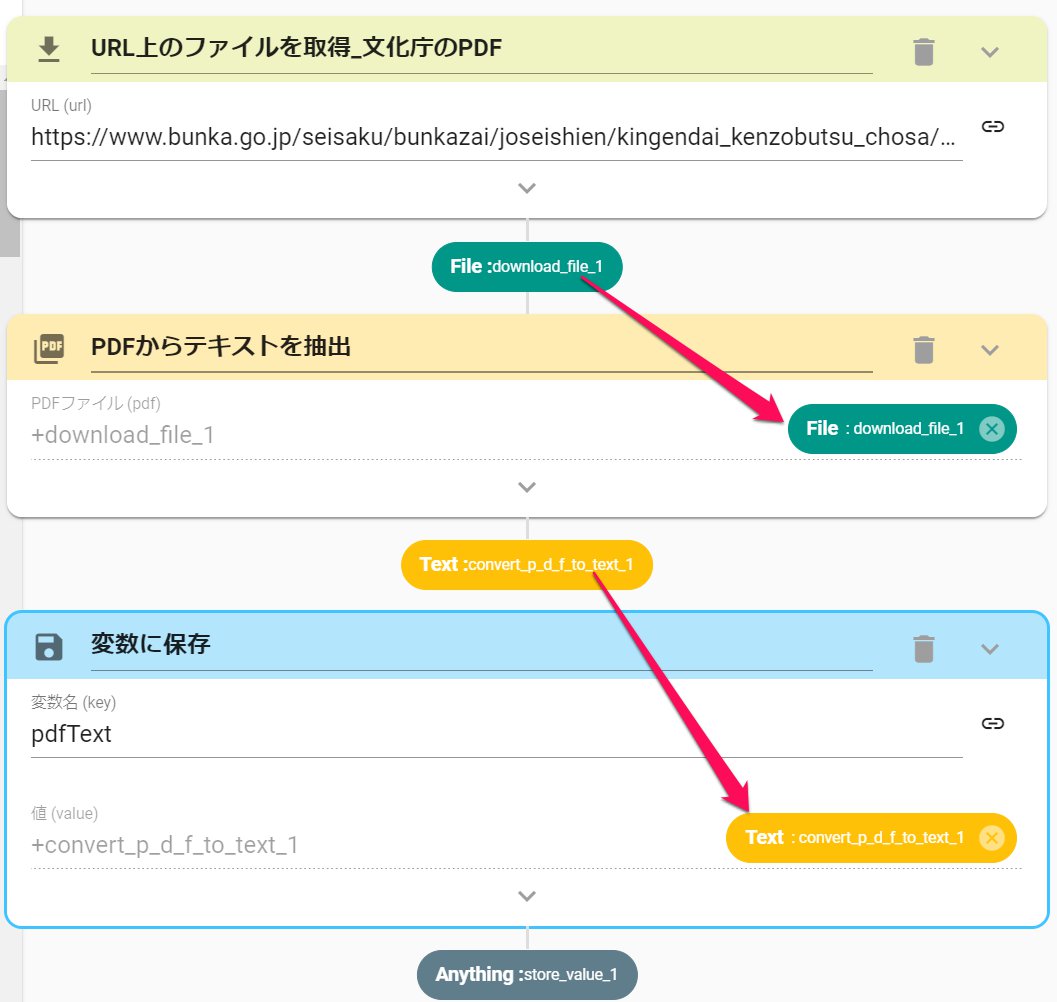
- DownloadFileアクションを設定します。
- PDFのURLを入力します
https://www.bunka.go.jp/seisaku/bunkazai/joseishien/kingendai_kenzobutsu_chosa/pdf/93784901_01.pdf
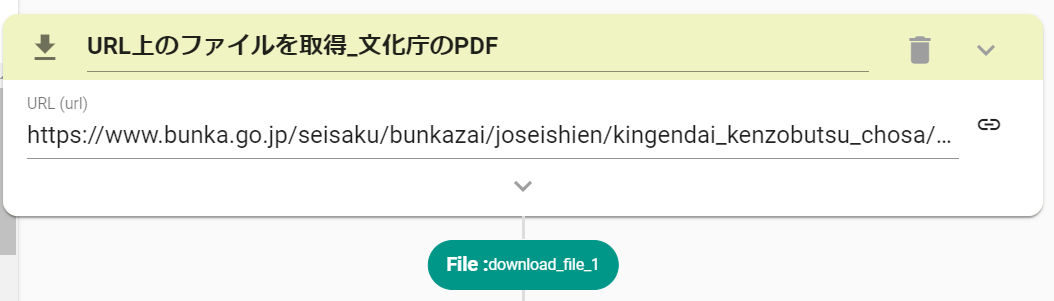
- ConvertPDFToText(PDFからテキストを抽出)を設定します。
- DownloadFileのアウトプットを紐づけます。

- StoreValue(変数に保存)を設定します。
- 変数名をpdftextとします
- 値はConvertPDFTotextのアウトプットとします。
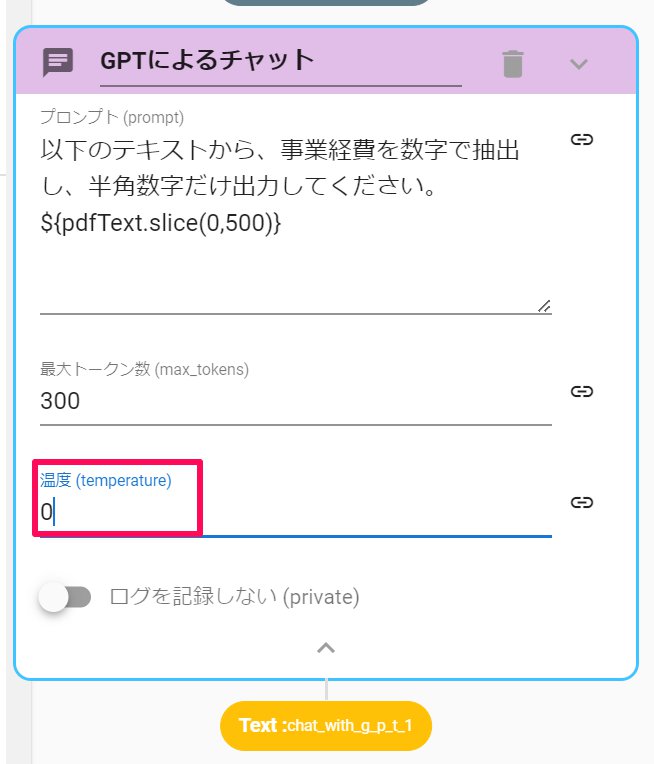
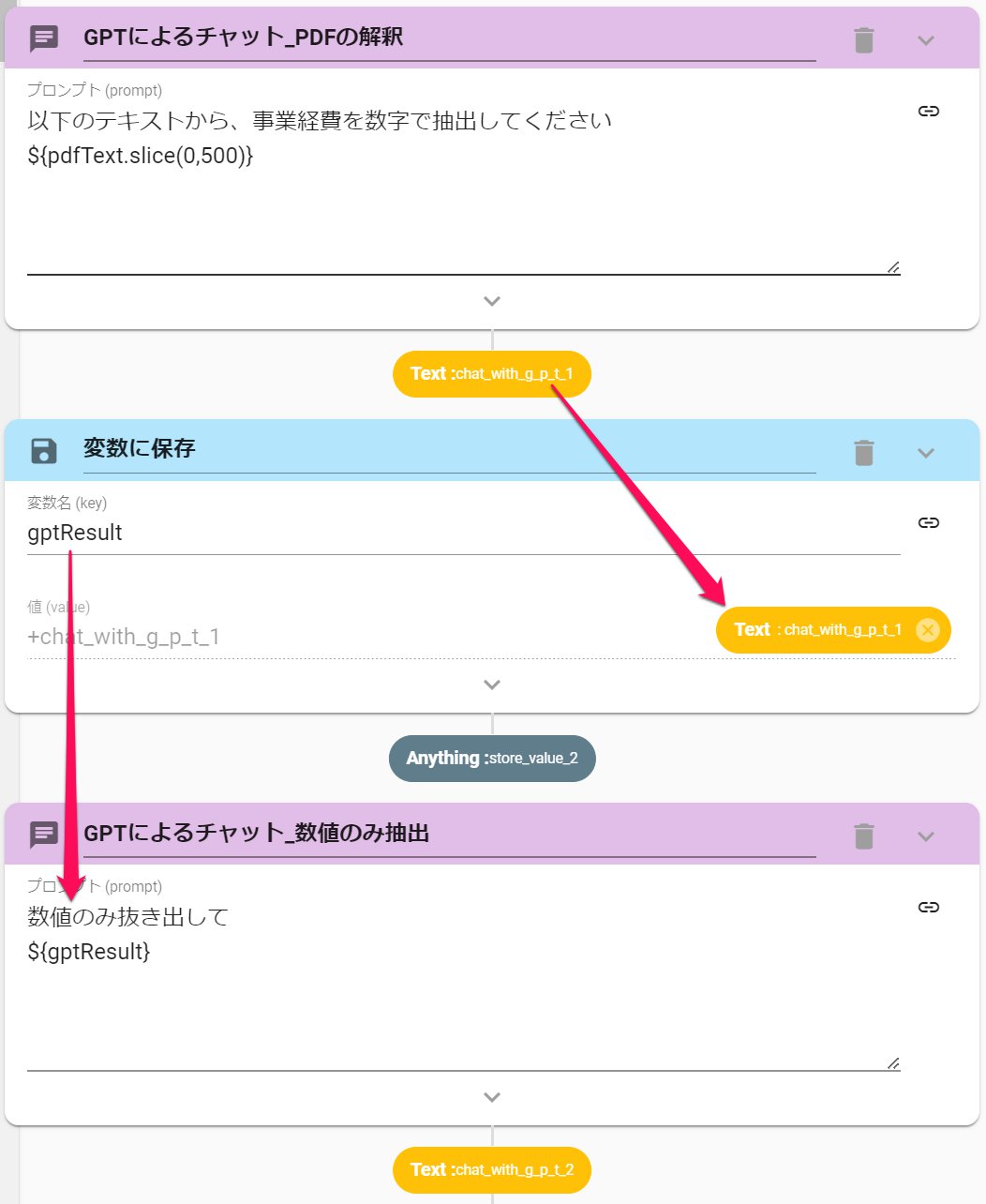
今回の抽出対象は「事業経費」です。事業経費を抽出するための命令文を書き込みます。
- ChatWithGPTを設定します。
- 命令文に以下を入力します
以下の文章から、事業経費を数字で抽出してください
${pdfText.slice(0,500)}
- アクションの詳細設定を開きます
- 温度(temperature)を0にします。
この状態でワークフローを実行してみましょう
※slice(0,500)について…
ChatGPTに読み込ませる情報量が多いと、アクションがエラーしてしまう場合があります。これを防止するために、前半500文字を読み込ませています。
※温度(temperature)について…
0にすると、確定的/確実性の高い返答を行ないます。2にすると、より多様かつ冒険的な返答を行ないます(的外れな回答を行う場合もあります)。デフォルトは、1となっています。
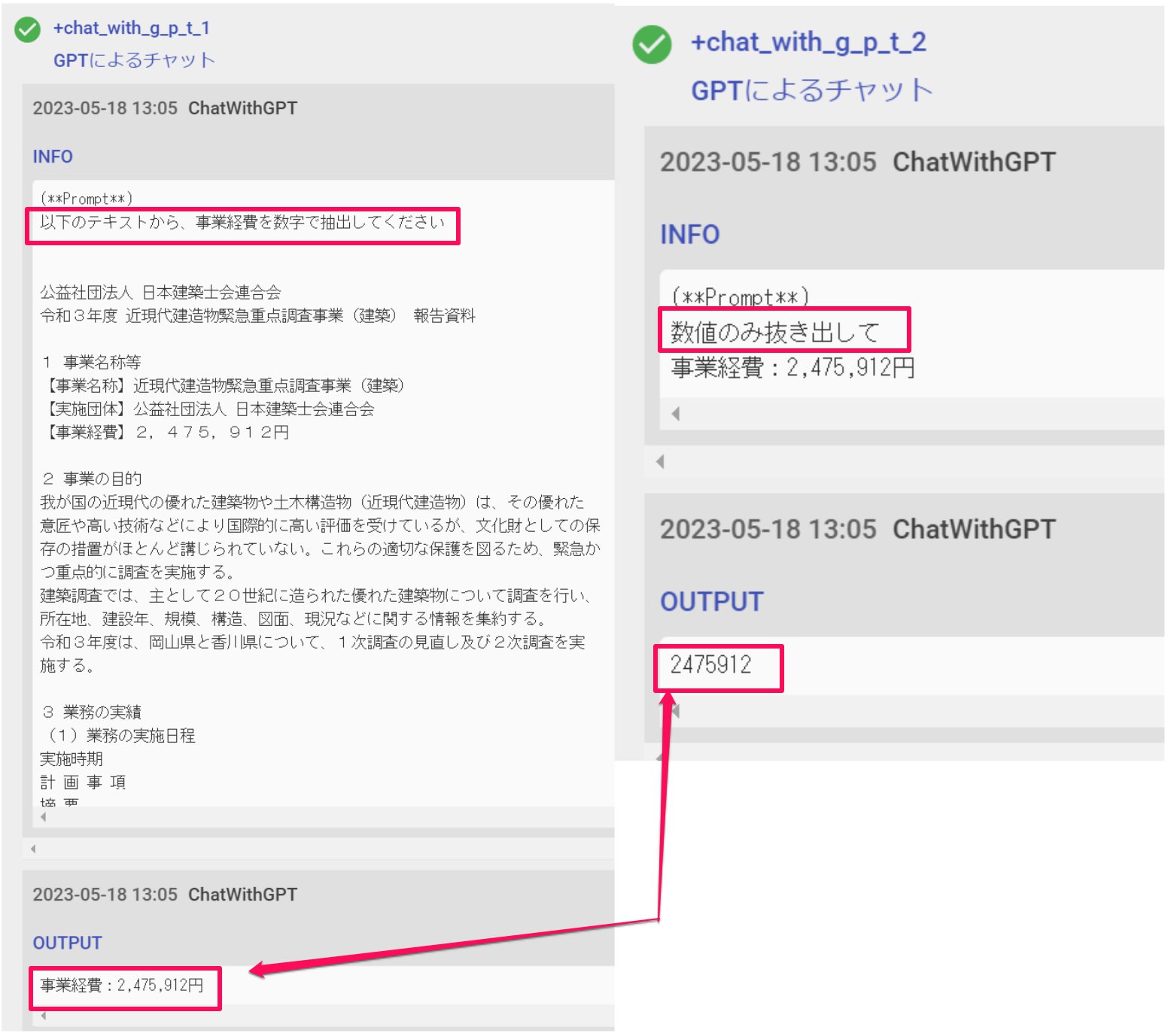
上述の命令文であると、以下が出力されることが多いです
「事業経費:xxxx円」
ここから数値のみを抜き出す操作も、ChatWithGPTアクションで実現できます。
※ただし、この例では「ReplaceText(検索して置換)」アクションを使用したほうが早くて確実です
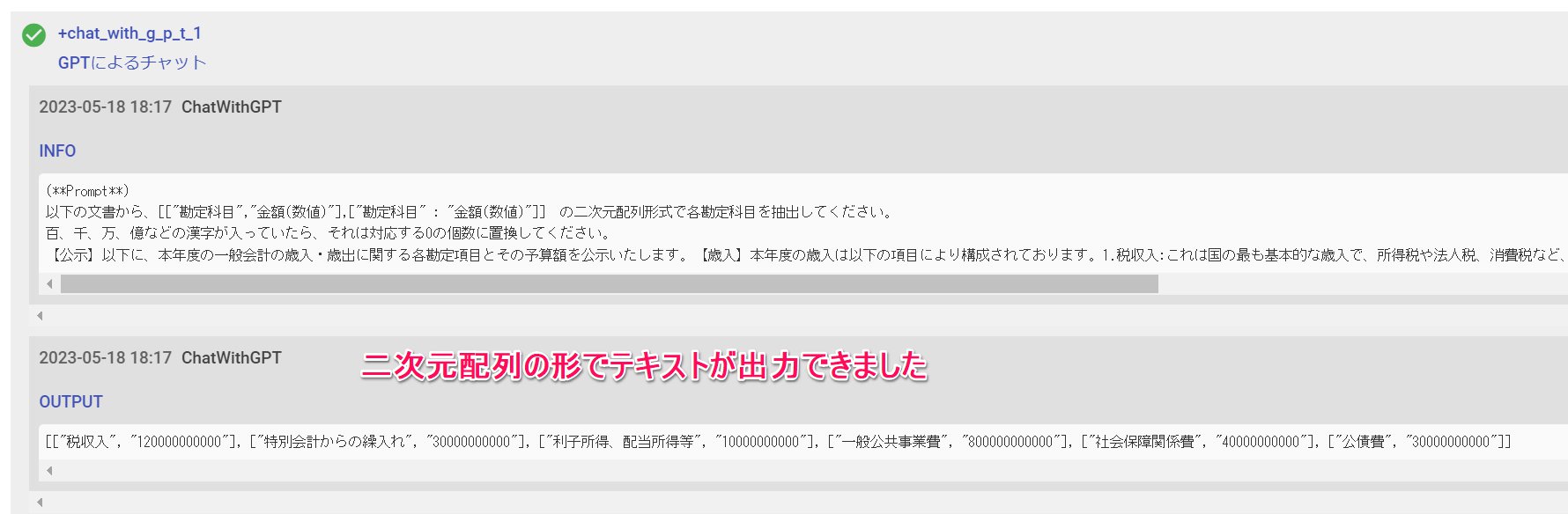
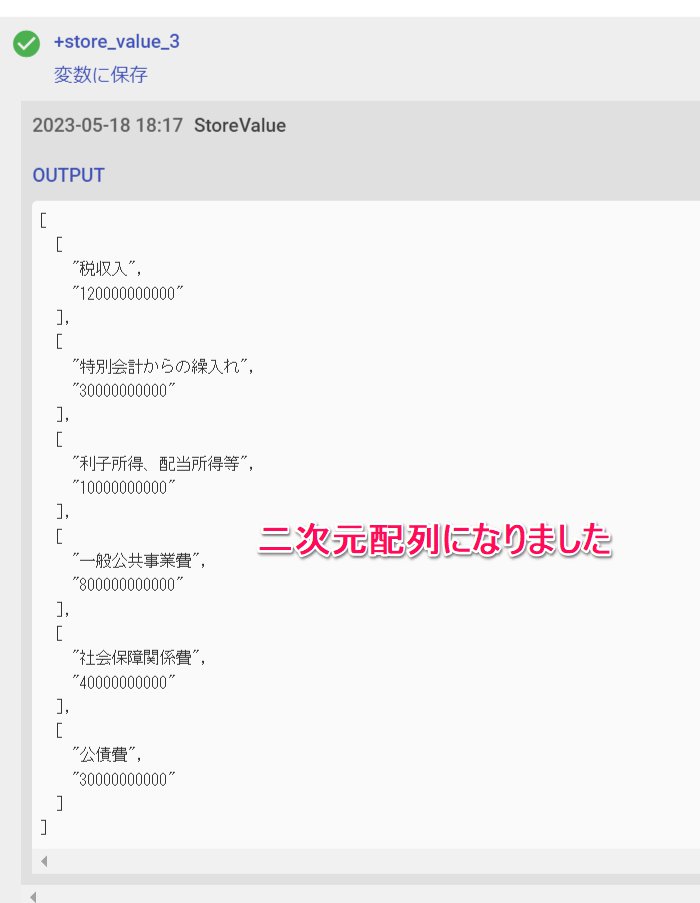
あるPDFから、複数の勘定科目を二次元配列にして抜き出すこともできます。
この二次元配列は、シートへの貼り付けや、CSV作成の元情報として利用することができます。
以下のサンプルPDF(架空の公示, GPT4で生成)から各勘定項目を抜き出すサンプルを紹介します。実行結果とワークフロー本体は、このエリアの直下をご参照ください。
# URL上のファイルを取得_文化庁のPDF
+download_file_1:
action>: DownloadFile
url: 'https://www.bunka.go.jp/seisaku/bunkazai/joseishien/kingendai_kenzobutsu_chosa/pdf/93784901_01.pdf'
private: false
# PDFからテキストを抽出
+convert_p_d_f_to_text_1:
action>: ConvertPDFToText
pdf: +download_file_1
private: false
# 変数に保存
+store_value_1:
action>: StoreValue
key: pdfText
value: +convert_p_d_f_to_text_1
private: false
# GPTによるチャット_PDFの解釈
+chat_with_g_p_t_1:
action>: ChatWithGPT
prompt: "以下のテキストから、事業経費を数字で抽出してください\n${pdfText.slice(0,500)}"
max_tokens: 300
temperature: '0'
private: false
# 変数に保存
+store_value_2:
action>: StoreValue
key: gptResult
value: +chat_with_g_p_t_1
private: false
# GPTによるチャット_数値のみ抽出
+chat_with_g_p_t_2:
action>: ChatWithGPT
prompt: "数値のみ抜き出して\n${gptResult}"
max_tokens: 300
temperature: 1
private: false
# 検索して置換_半角数字以外置換
+replace_text_1:
action>: ReplaceText
text: +chat_with_g_p_t_1
find: '\D'
use_regex: true
replace_with: ''
private: false
最後にCSVを作成しています。
# URL上のファイルを取得_サンプルPDF
+download_file_1:
action>: DownloadFile
url: 'https://support.autoro.io/wp-content/uploads/2023/05/GPT4%E3%81%AE%E5%85%AC%E7%A4%BA.pdf'
private: false
# PDFからテキストを抽出
+convert_p_d_f_to_text_1:
action>: ConvertPDFToText
pdf: +download_file_1
private: false
# 変数に保存
+store_value_1:
action>: StoreValue
key: pdfText
value: +convert_p_d_f_to_text_1
private: false
# GPTによるチャット_二次元配列生成を依頼
+chat_with_g_p_t_1:
action>: ChatWithGPT
prompt: "以下の文書から、[[\"勘定科目\",\"金額(数値)\"],[\"勘定科目\" : \"金額(数値)\"]] の二次元配列形式で各勘定科目を抽出してください。\n百、千、万、億などの漢字が入っていたら、それは対応する0の個数に置換してください。\n${pdfText.replace(/\\n/g,\"\")}"
max_tokens: 300
temperature: '0'
private: false
# 変数に保存_この時点ではテキスト
+store_value_2:
action>: StoreValue
key: gptResult
value: +chat_with_g_p_t_1
private: false
# 変数に保存_テキストを二次元配列にする
+store_value_3:
action>: StoreValue
key: gptResultArray
value: ${JSON.parse(gptResult)}
private: false
# CSVを作成
+write_c_s_v_1:
action>: WriteCSV
filename: 'gptSample.csv'
table: ${gptResultArray}
bom: true
private: false
# ファイルを保存_AUTOROローカルストレージに保存
+save_file_1:
action>: SaveFile
provider: local
filename: +write_c_s_v_1
createPath: false
private: false
トップ記事の情報を取得するために必要な情報は、以下4つが考えられます。
- アクセス対象のURL(カテゴリのトップページなど)
- トップページ内の1番目の記事のCSSセレクタ
- 記事内の本文部位のCSSセレクタ
- 記事のURL
これらの情報を取得するためのワークフローサンプルは、以下となります。
これはエディタモードから複製可能です。
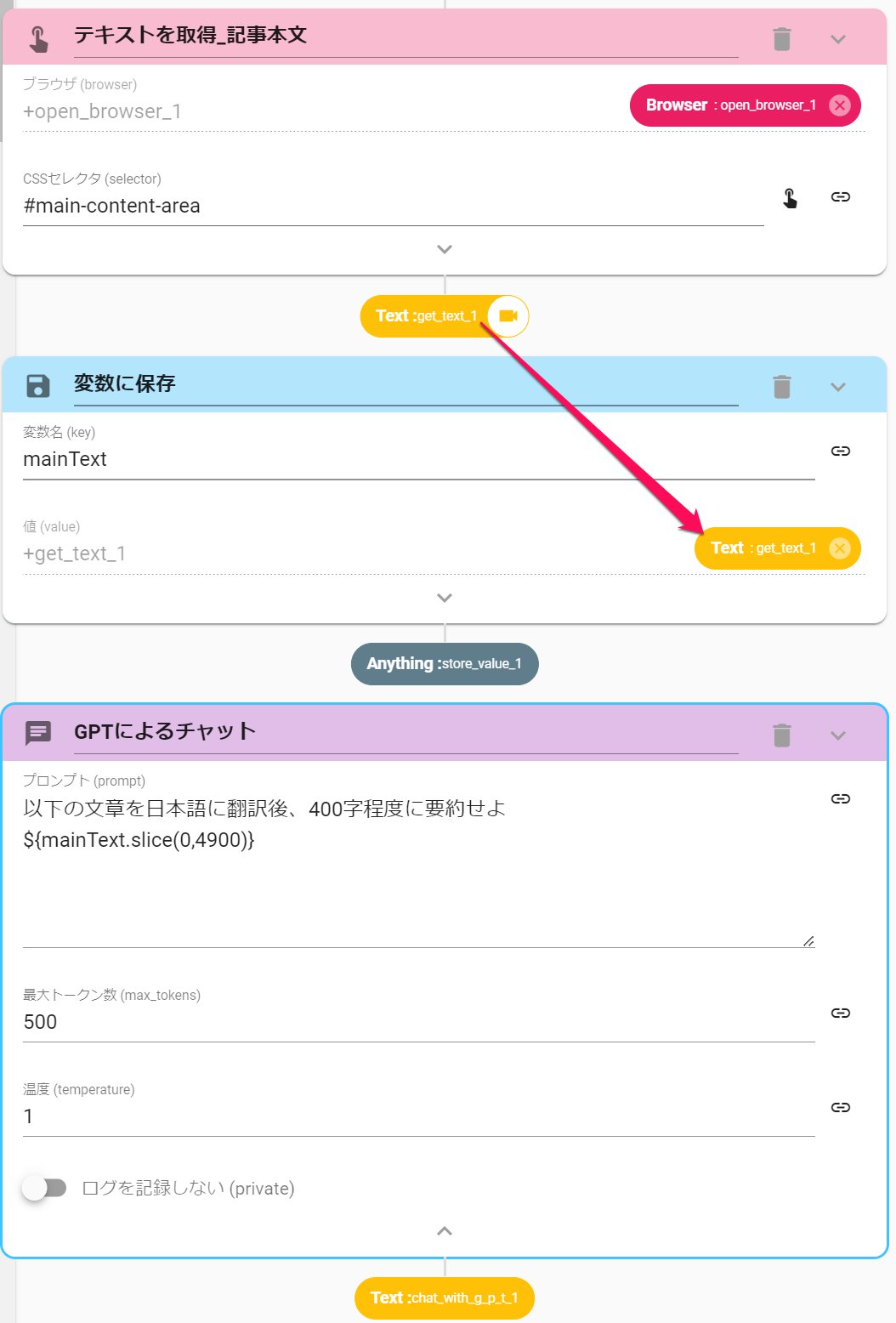
# ブラウザを開く_アルジャジーラのartsカテゴリトップ +open_browser_1: action>: OpenBrowser url: 'https://www.aljazeera.net/arts/' lang: 'ja-JP' timeZone: 'Asia/Tokyo' headless: true windowSize: '1920 x 1080' useShadowDomSelector: false private: false # クリック_トップ記事 +click_1: action>: Click browser: +open_browser_1 selector: 'h3 a' confirm: true ignoreError: true timeout: 30000 private: false # テキストを取得_記事本文 +get_text_1: action>: GetText browser: +open_browser_1 selector: '#main-content-area' ignoreError: true private: false # 変数に保存_記事本文 +store_value_1: action>: StoreValue key: mainText value: +get_text_1 private: false # URLを取得_メッセージ内に付加するURL +get_u_r_l_1: action>: GetURL browser: +open_browser_1 private: false # 変数に保存_記事URL +store_value_2: action>: StoreValue key: articleURL value: +get_u_r_l_1 private: false
ChatWithGPTアクションをワークフロー内に設置し、今回の目的に適した命令文を作成します。
- ChatWithGPTアクションの命令文に以下を入力します。
以下の文章を日本語に翻訳後、400字程度に要約せよ
- 「以下の文章」として、トップ記事の本文を変数化した値の、前方4000文字程度を与えます。(命令文が長すぎると処理できない場合があるためです)
${変数名.slice(0,3900}) - アクションの詳細設定を開きます。
- 今回は400文字程度での要約を指示したため、ChatGPTが400文字程度を出力できるように「トークン」を500程度に設定します。
この状態でワークフローを実行してみると、結果がセッションログ内に表示されます。
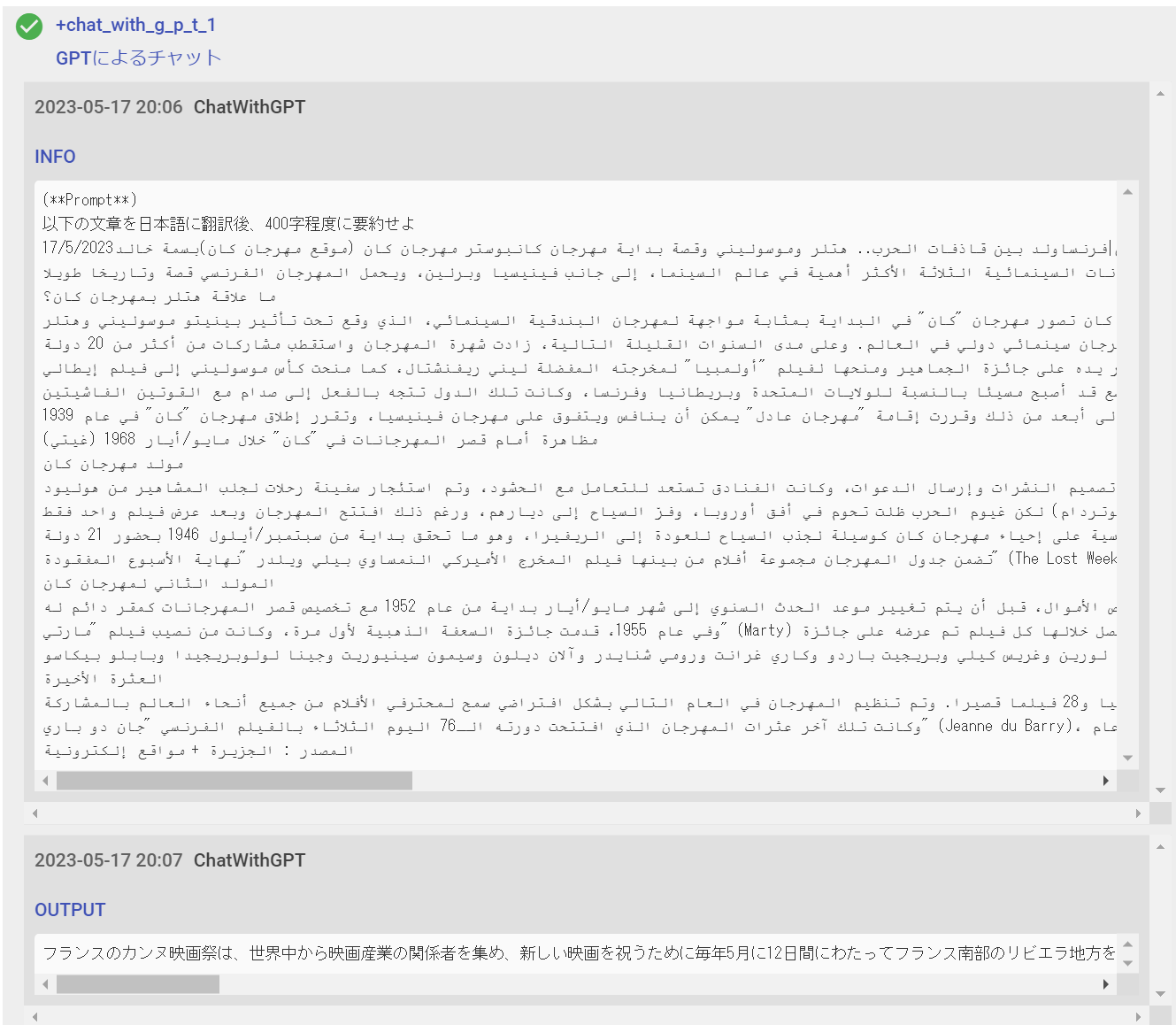
※トークン(max_tokens)について
最大で4096まで設定できます。(日本語で2,500文字程度)
トークンが大きい場合は、返答の生成に時間がかかる場合があります。
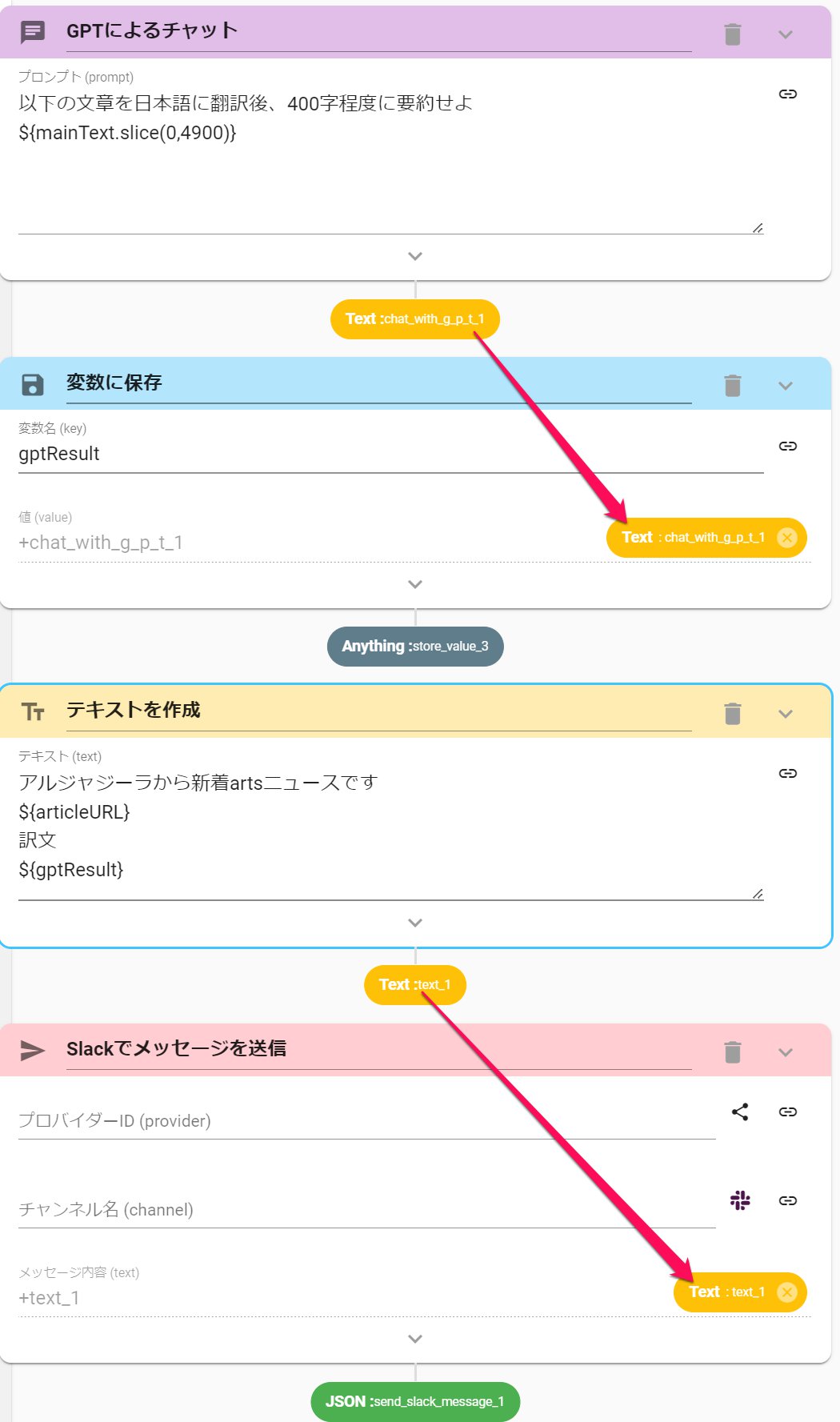
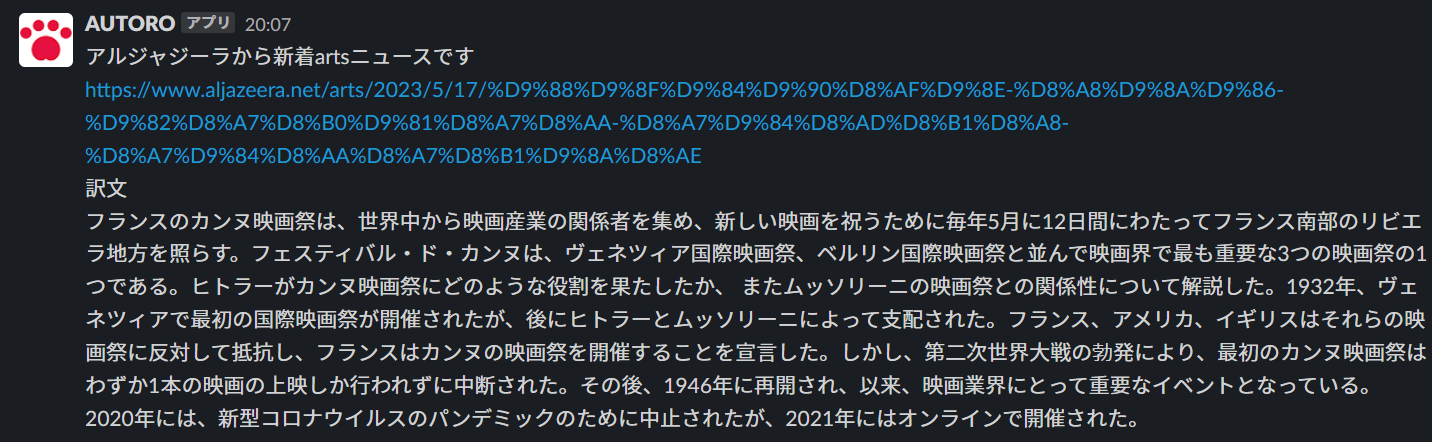
Textアクションを使用して、記事のURLや翻訳&要約後の文章を合体させることが可能です。
このTextをSlackに送信する例は、下記の「ワークフロー設定例」をご確認ください。
※AUTOROとSlackの連携方法はこちらです。
# ブラウザを開く
+open_browser_1:
action>: OpenBrowser
url: 'https://www.aljazeera.net/arts/'
lang: 'ja-JP'
timeZone: 'Asia/Tokyo'
headless: true
windowSize: '1920 x 1080'
useShadowDomSelector: false
private: false
# クリック_トップ記事
+click_1:
action>: Click
browser: +open_browser_1
selector: 'h3 a'
confirm: true
ignoreError: true
timeout: 30000
private: false
# テキストを取得_記事本文
+get_text_1:
action>: GetText
browser: +open_browser_1
selector: '#main-content-area'
ignoreError: true
private: false
# 変数に保存
+store_value_1:
action>: StoreValue
key: mainText
value: +get_text_1
private: false
# URLを取得_メッセージ添付用
+get_u_r_l_1:
action>: GetURL
browser: +open_browser_1
private: false
# 変数に保存
+store_value_2:
action>: StoreValue
key: articleURL
value: +get_u_r_l_1
private: false
# GPTによるチャット
+chat_with_g_p_t_1:
action>: ChatWithGPT
prompt: "以下の文章を日本語に翻訳後、400字程度に要約せよ\n${mainText.slice(0,4900)}"
max_tokens: 600
temperature: 1
private: false
# 変数に保存
+store_value_3:
action>: StoreValue
key: gptResult
value: +chat_with_g_p_t_1
private: false
# テキストを作成
+text_1:
action>: Text
text: "アルジャジーラから新着artsニュースです\n${articleURL}\n訳文\n${gptResult}"
private: false
# Slackでメッセージを送信
+send_slack_message_1:
action>: SendSlackMessage
provider: 'プロバイダID'
channel: 'チャンネル名'
text: +text_1
send_select: false
response_message: false
private: false
meta:
display:
サイトマップとは、あるWebサイトの中にある全てのページが、どんな内容で、どこにあるのかをURLを含めて記載しているxmlファイルを言います。
これは、Googleなどの検索エンジンに気付いてもらうために設定されています。
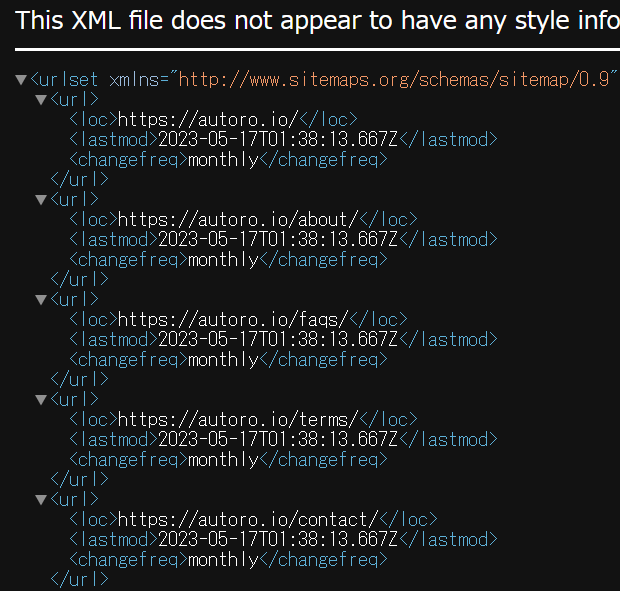
このサイトマップをAUTOROのChatWithGPTのアクションに読み込ませて適切な命令を下すと、「会社概要」「企業情報」といったページのURLを抽出できます。
さらにそのURLにアクセス後、中の文字情報を取得してChatGPTに読み込ませて適切な命令を下せば、企業の代表者名を取得することもできるようになります。
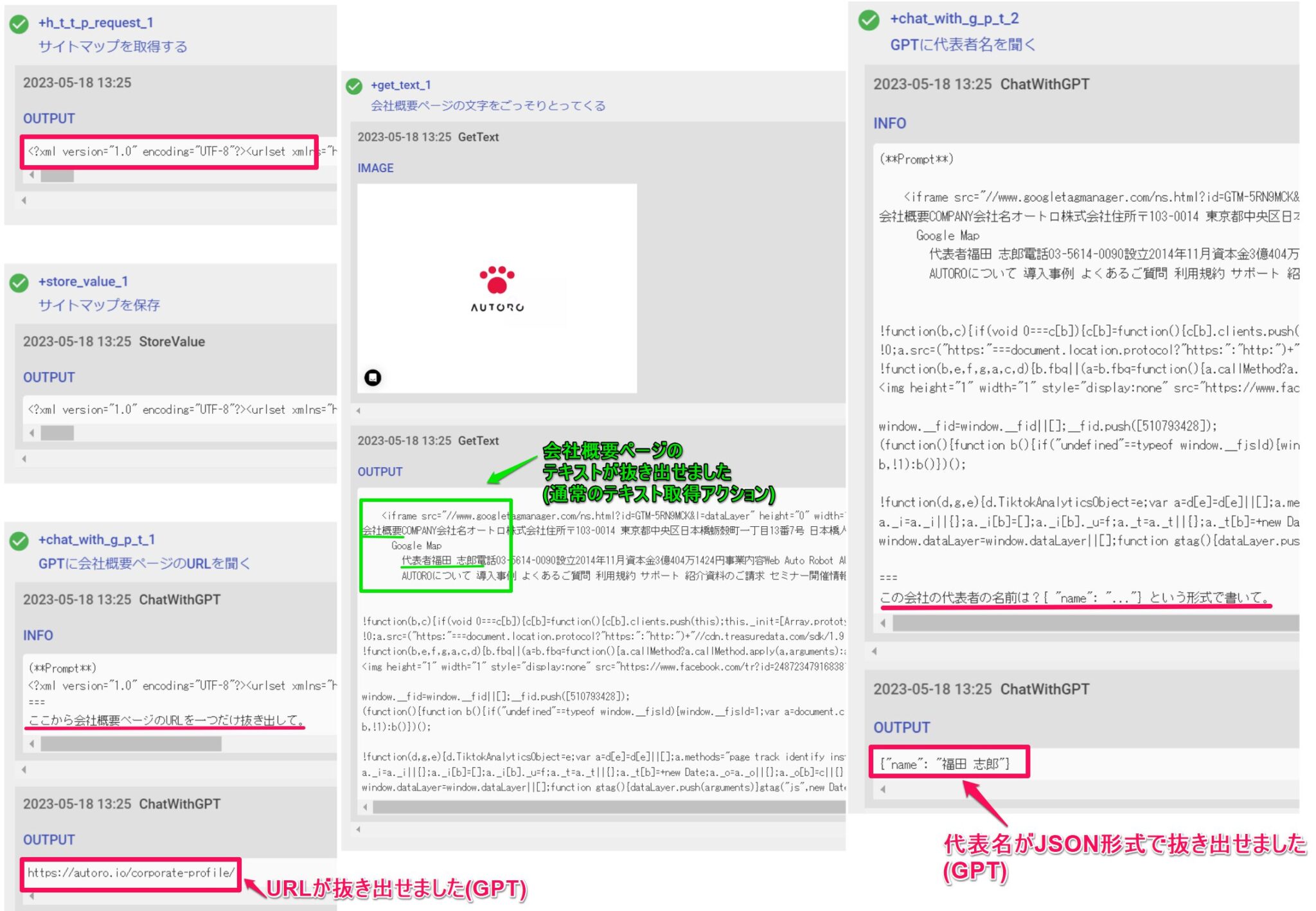
サイトマップ(sitemap.xml)の中身は、HTTPリクエストアクションで取得できます。
- HTTPRequestアクションを設定します。
- サイトマップのURLを入力します
- リクエストメソッドにGETを指定します
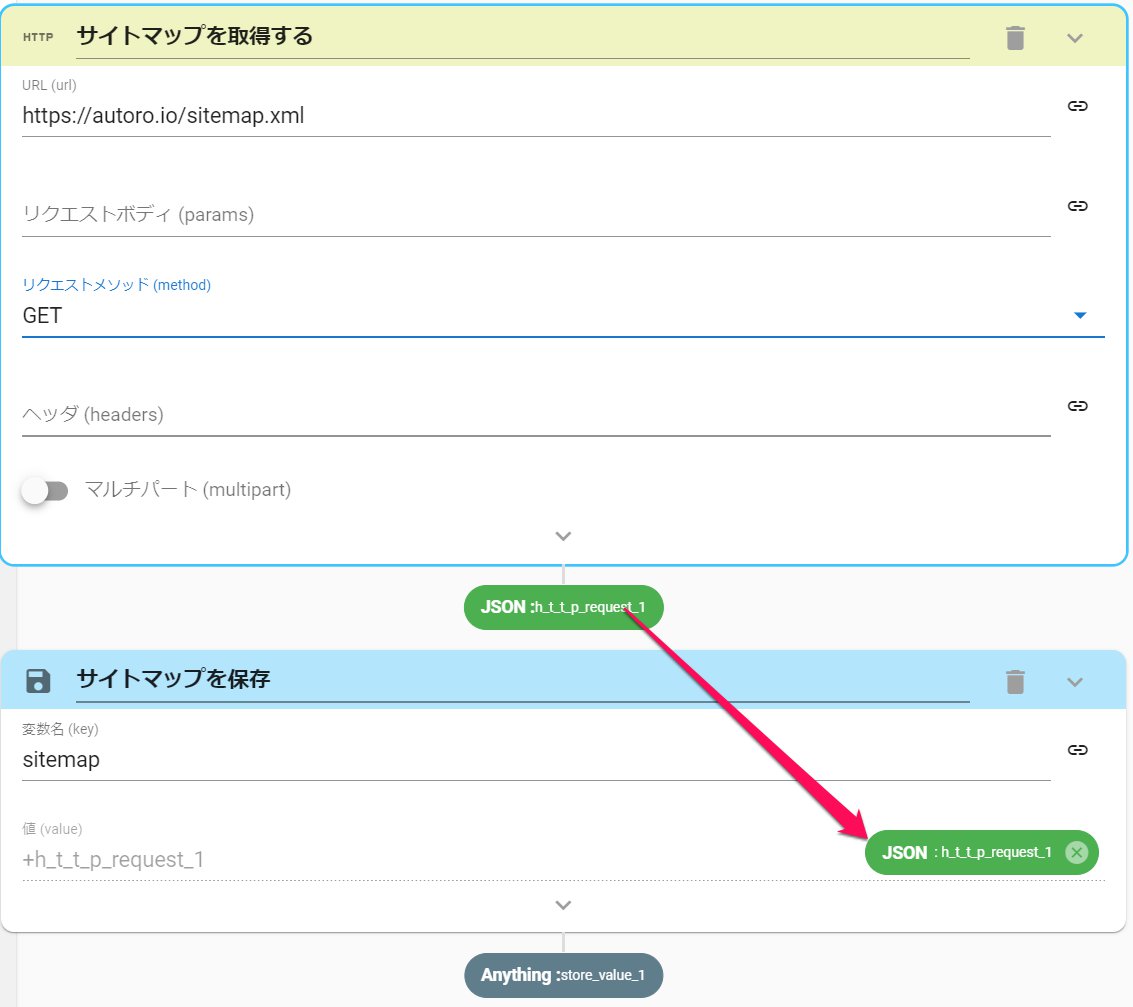
- 変数に保存を設定します
- 変数名をsitemapにします
- 値をHTTPRequestのアウトプットにします
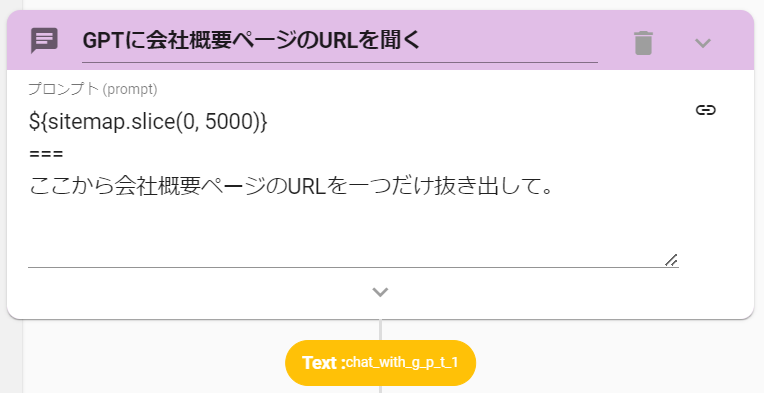
- ChatWithGPTアクションを設定します。
- 以下の命令文を打ち込みます。
${sitemap.slice(0, 5000)}
===
ここから会社概要ページのURLを一つだけ抜き出して。
- OpenBrowserを設定します
- URLに2のChatWithGPTのアウトプットを指定します
- GetTextアクションを設定します
- CSSセレクタにbodyと入力します。
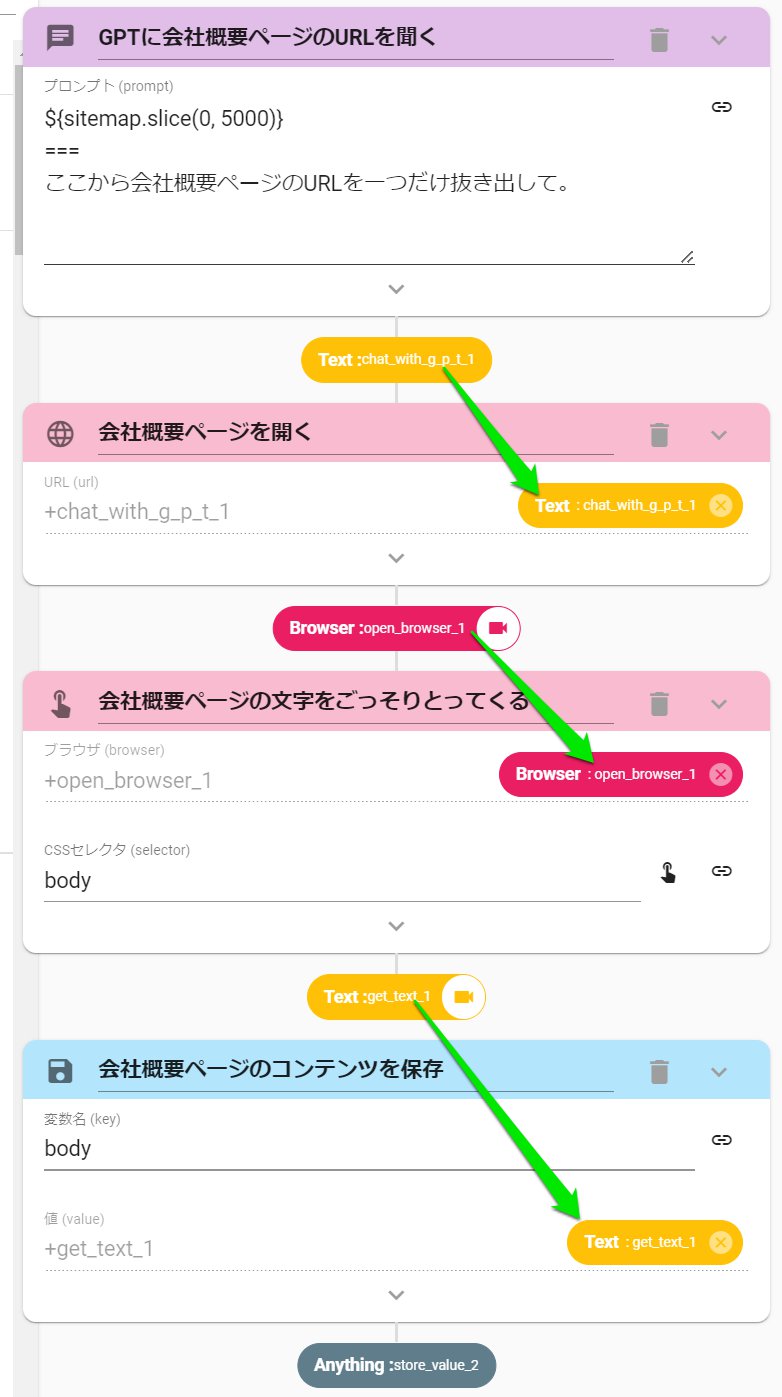
- 変数に保存を設定します
- 変数名をbodyにします
- 値をGetTextのアウトプットにします
会社概要ページの本文が取得できています。あとはここから代表名を抽出してもらいましょう。
ここでは、ロボットが解釈しやすいオブジェクト(JSON)形式で抽出してもらいます。
- ChatWithGPTを設定します
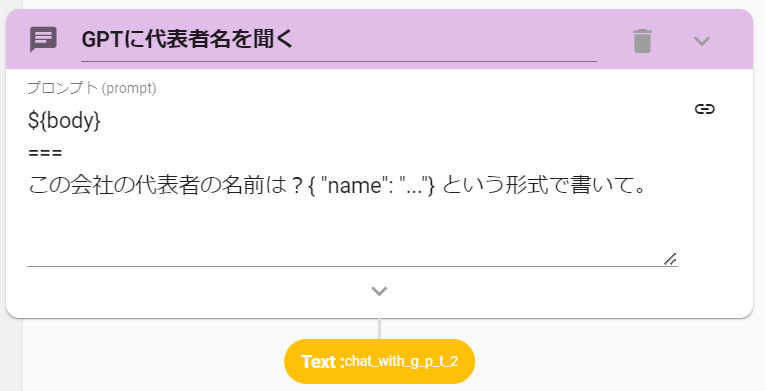
- 以下の命令文を設定します
${body}
===
この会社の代表者の名前は?{ "name": "..."} という形式で書いて。
# サイトマップを取得する
+h_t_t_p_request_1:
action>: HTTPRequest
url: 'https://autoro.io/sitemap.xml'
params: ''
method: GET
headers: ''
multipart: false
private: false
# サイトマップを保存
+store_value_1:
action>: StoreValue
key: sitemap
value: +h_t_t_p_request_1
private: false
# GPTに会社概要ページのURLを聞く
+chat_with_g_p_t_1:
action>: ChatWithGPT
prompt: "${sitemap.slice(0, 5000)}\n===\nここから会社概要ページのURLを一つだけ抜き出して。"
max_tokens: 300
temperature: 1
private: false
# 会社概要ページを開く
+open_browser_1:
action>: OpenBrowser
url: +chat_with_g_p_t_1
lang: 'ja-JP'
headless: true
useShadowDomSelector: false
private: false
# 会社概要ページの文字をごっそりとってくる
+get_text_1:
action>: GetText
browser: +open_browser_1
selector: body
ignoreError: true
private: false
# 会社概要ページのコンテンツを保存
+store_value_2:
action>: StoreValue
key: body
value: +get_text_1
private: false
# GPTに代表者名を聞く
+chat_with_g_p_t_2:
action>: ChatWithGPT
prompt: "${body}\n===\nこの会社の代表者の名前は?{ \"name\": \"...\"} という形式で書いて。"
max_tokens: 300
temperature: 1
private: false
# ブラウザを開く
+open_browser_1:
action>: OpenBrowser
url: 'https://autoro.io/'
lang: 'ja-JP'
headless: true
useShadowDomSelector: false
private: false
# ページ内でJavaScriptを実行する_outerHTML, 企業URLの2列で抜き出す
+inject_script_3:
action>: InjectScript
browser: +open_browser_1
code: "const links = [\n ...document.querySelectorAll(\"footer a\"),\n ...document.querySelectorAll(\"a\")\n]; //フッター内リンク優先\nconst arr = [];\nfor (i = 0; links.length > i; i++) {\n // arr.push(links[i].href);\n // arr.push(links[i].outerHTML);\n arr.push([links[i].outerHTML, links[i].href]);\n}\n[...new Set(arr)];\n"
returnValue: true
private: false
# 変数に保存
+store_value_5:
action>: StoreValue
key: links
value: +inject_script_3
private: false
# GPTによるチャット
+chat_with_g_p_t_1:
action>: ChatWithGPT
prompt: "次のURL一覧から、会社概要ページのURLを持つ行を1つ抜き出して、2列目の値を出力しなさい。ただし、該当する行がなければ false とだけ答えなさい。\n===\n${JSON.stringify(links).slice(0,5000)}"
max_tokens: 300
temperature: '0'
private: false
# 真のとき_urlがあった
+if_1:
if>: +chat_with_g_p_t_1
_do:
# エラーを捕捉する
+try_1:
try>: isError
_do:
# URLへ遷移
+go_to_2:
action>: GoTo
browser: +open_browser_1
url: +chat_with_g_p_t_1
private: false
# 会社概要ページの文字をごっそりとってくる
+get_text_1:
action>: GetText
browser: +open_browser_1
selector: body
ignoreError: true
private: false
# 会社概要ページのコンテンツを保存
+store_value_2:
action>: StoreValue
key: body
value: +get_text_1
private: false
# GPTに代表者名を聞く
+chat_with_g_p_t_2:
action>: ChatWithGPT
prompt: "${body}\n===\nこの会社の代表者の名前は?{ \"name\": \"...\"} という形式で書いて。"
max_tokens: 300
temperature: 1
private: false
# ブラウザを閉じる
+close_browser_1:
action>: CloseBrowser
browser: +open_browser_1
private: false