ChatGPTを使用する
AUTOROでは、ワークフロー内でChatGPTを利用するためにChatWithLLMアクション(LLMによるチャット)を用意しています。
このアクションに命令文(プロンプト)を入力すると、ChatGPTからの応答をテキストとして利用できます。
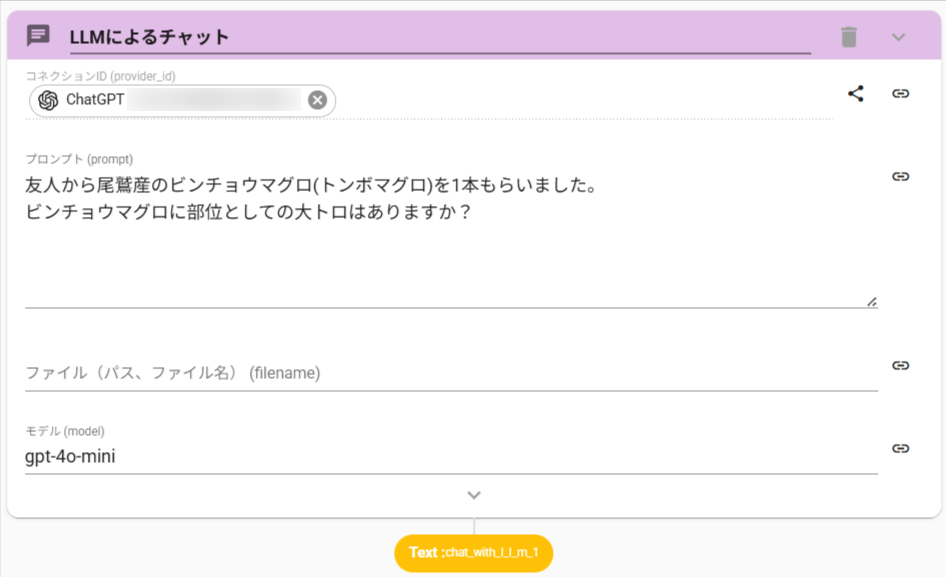

ChatWithLLMアクションは、OpenAI APIを使用してChatGPTを操作します。
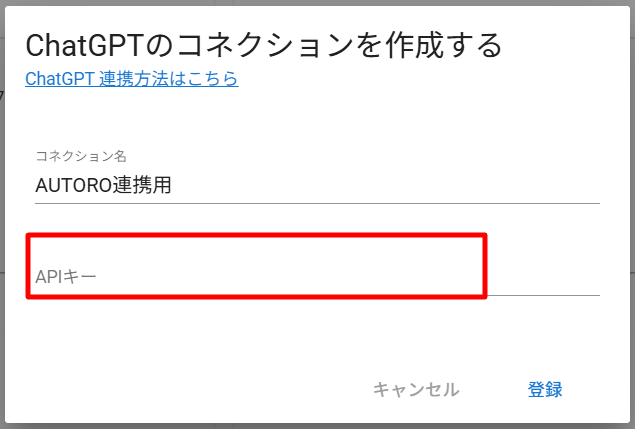
ChatGPT用コネクション作成のため、OpenAI APIが利用可能なOpenAI Platformアカウントをご用意ください。
コネクション作成の際には、APIキーの登録が必要になります。
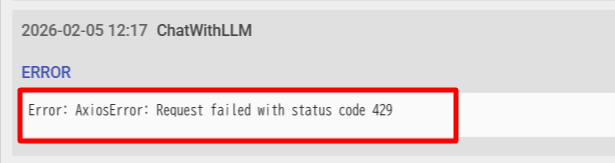
OpenAI Platformアカウント利用時でも、API利用のための クレジット(残高)がチャージされていない場合には、ChatWithLLMアクション実行時に以下のようなエラーになります。
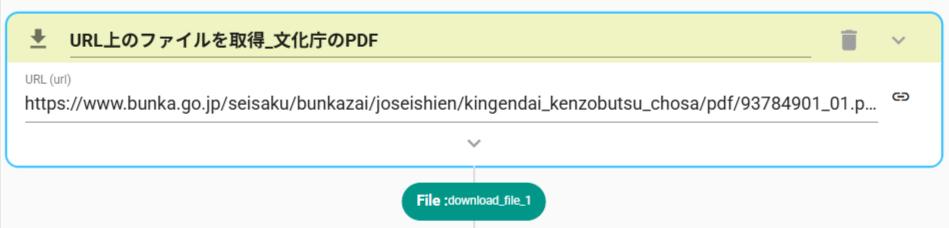
- DownloadFileアクション(URL上のファイルを取得)を設定します。
- PDFのURLを入力します
https://www.bunka.go.jp/seisaku/bunkazai/joseishien/kingendai_kenzobutsu_chosa/pdf/93784901_01.pdf
- PDFのURLを入力します
- ConvertPDFToTextアクション(PDFからテキストを抽出)を設定します。
- DownloadFileアクションのアウトプットを紐づけます。
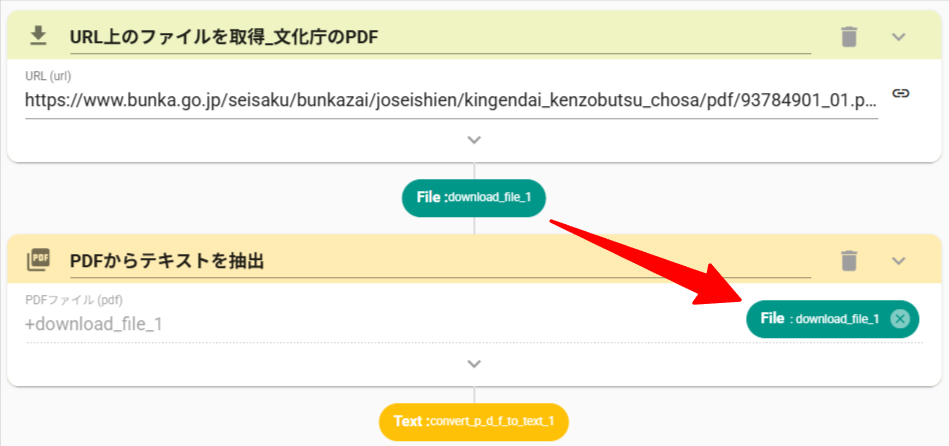
- StoreValueアクション(変数に保存)を設定します。
- 変数名を pdftext とします
- 値はConvertPDFTotextアクションのアウトプットとします

今回の抽出対象は「事業経費」です。事業経費を抽出するための命令文を書き込みます。
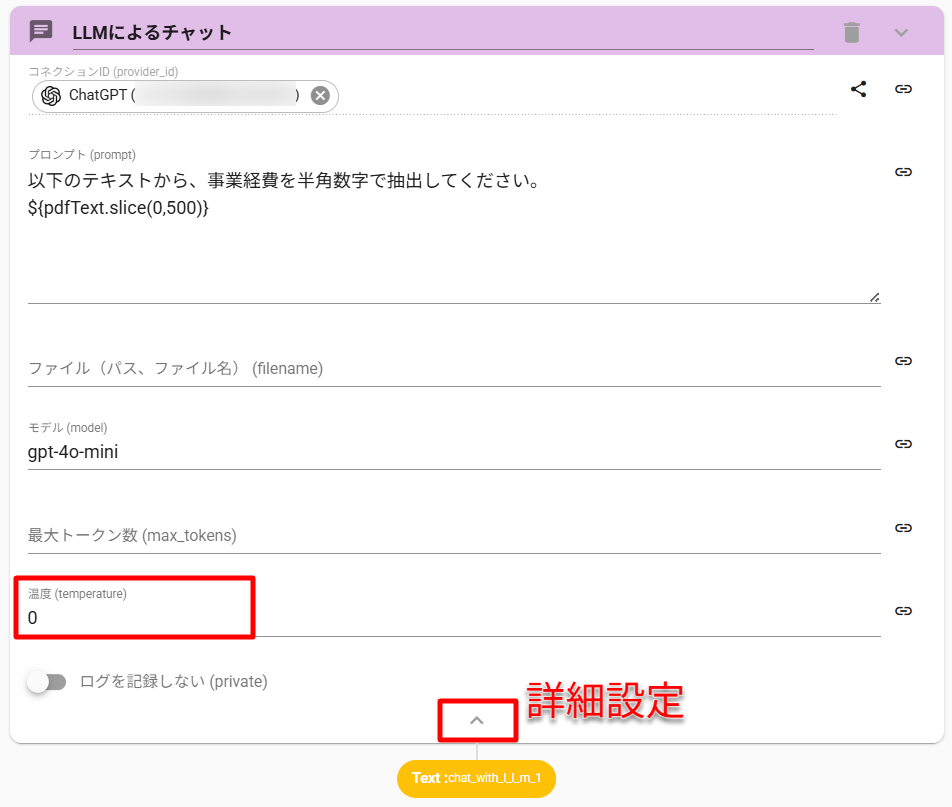
- ChatWithLLMアクションを設定します
- 命令文に以下を入力します
以下のテキストから、事業経費を半角数字で抽出してください。
${pdfText.slice(0,500)}
- アクションの詳細設定を開きます
- 温度(temperature)を0にします
この状態でワークフローを実行してみましょう。
※slice(0,500)について…
ChatGPTに読み込ませる情報量が多いと、アクションがエラーになってしまう場合があります。これを防止するために、前半500文字を読み込ませています。
※温度(temperature)について…
0 にすると、確定的/確実性の高い返答を行ないます。2 にすると、より多様かつ冒険的な返答を行ないます(的外れな回答を行う場合もあります)。デフォルトは、 1 となっています。
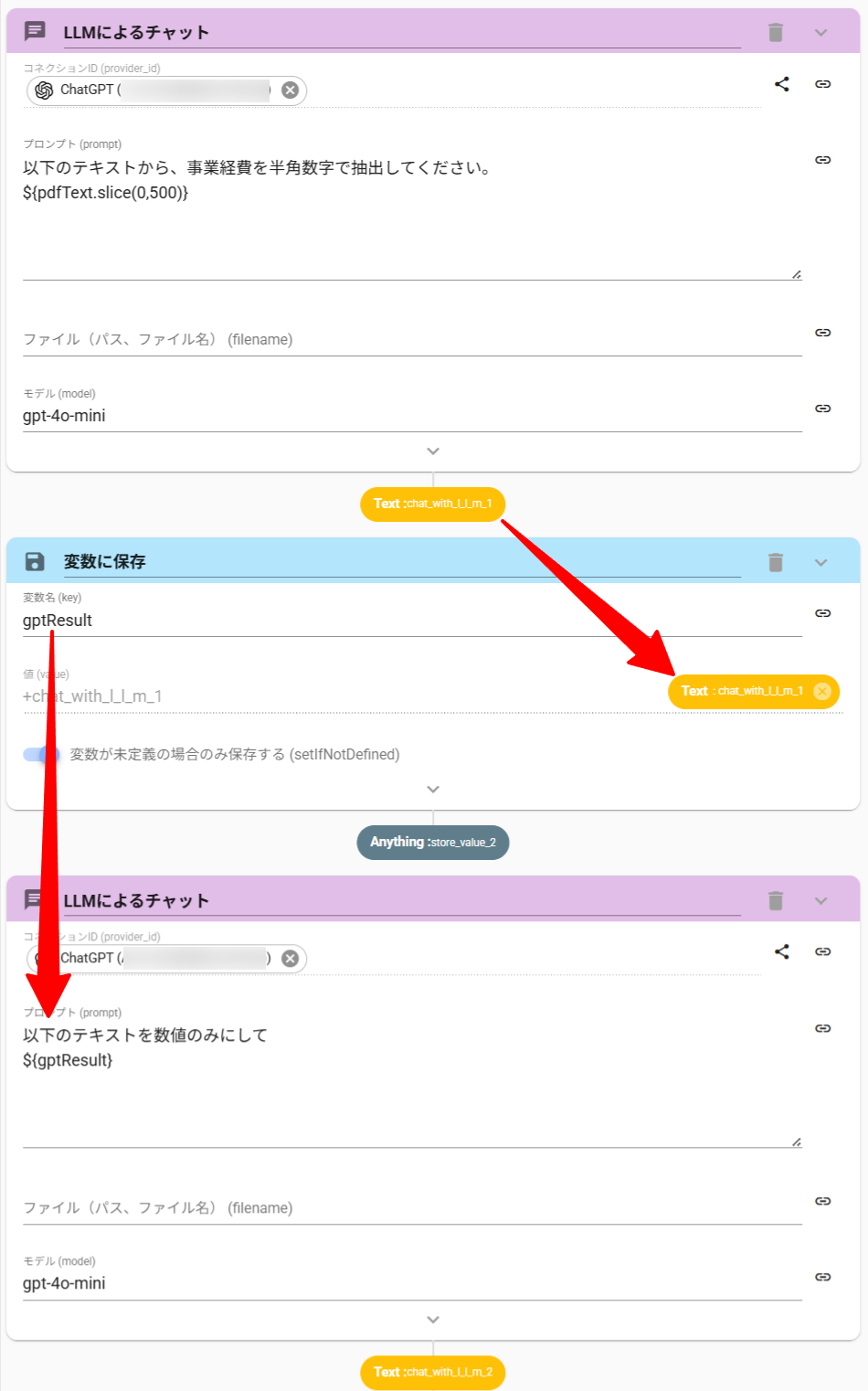
上述の命令文であると、以下が出力されることが多いです。
「事業経費は「xxxx円」です。」
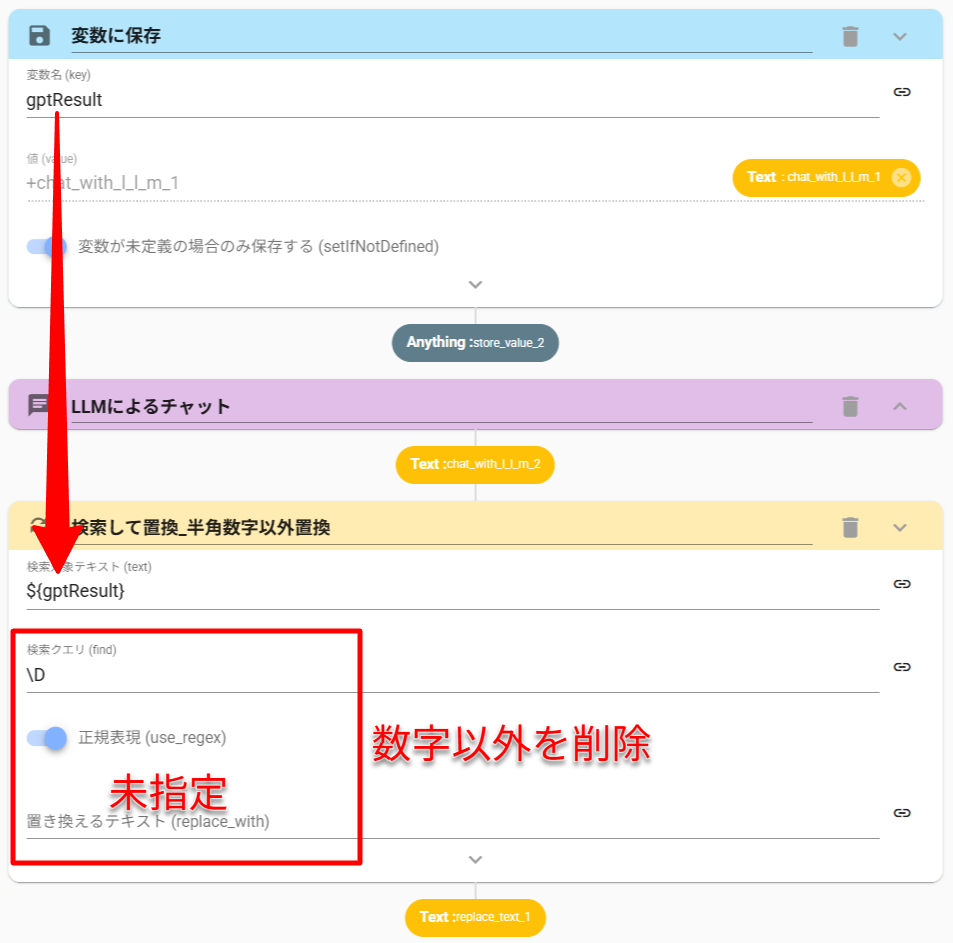
ここから数値のみを抜き出す操作も、ChatWithLLMアクションで実現できます。
ただし、この例ではReplaceTextアクション(検索して置換)を使用したほうが早くて確実です。
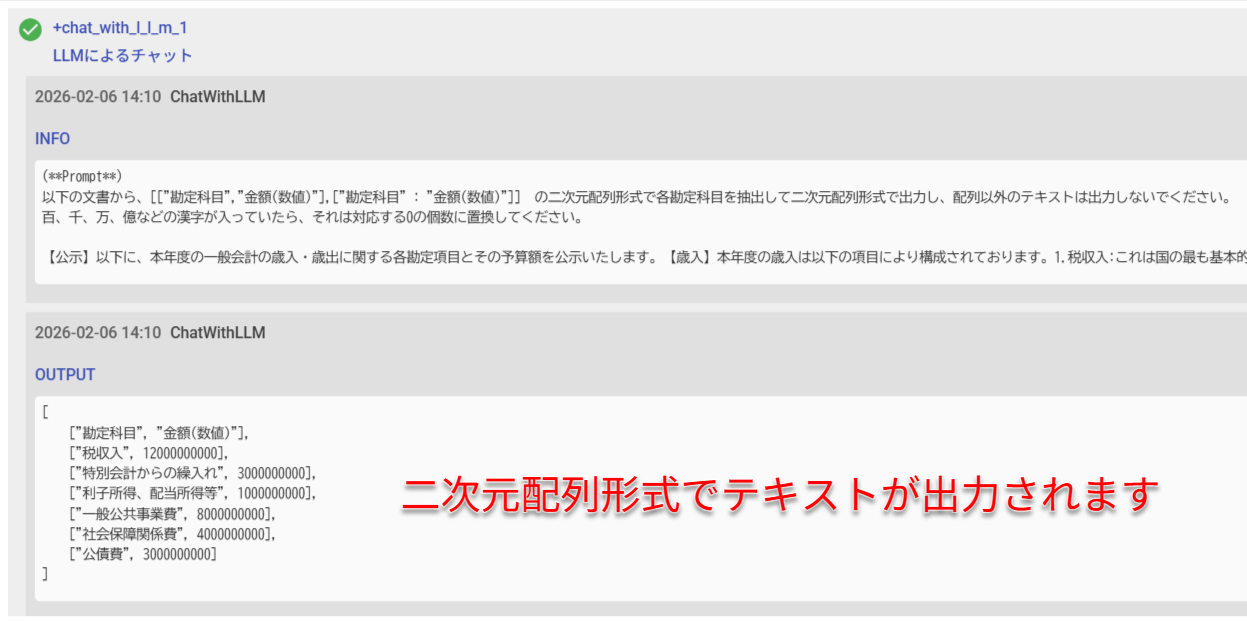
あるPDFから、複数の勘定科目を二次元配列にして抜き出すこともできます。
この二次元配列は、シートへの貼り付けや、CSV作成の元情報として利用することができます。
以下のサンプルPDF(架空の公示, GPT4で生成)から各勘定項目を抜き出すサンプルを紹介します。実行結果とワークフロー本体は、このエリアの直下をご参照ください。

# URL上のファイルを取得_文化庁のPDF
+download_file_1:
action>: DownloadFile
display_name>: 'URL上のファイルを取得_文化庁のPDF'
url: 'https://www.bunka.go.jp/seisaku/bunkazai/joseishien/kingendai_kenzobutsu_chosa/pdf/93784901_01.pdf'
private: false
meta:
action:
disabled: false
# PDFからテキストを抽出
+convert_p_d_f_to_text_1:
action>: ConvertPDFToText
display_name>: 'PDFからテキストを抽出'
pdf: +download_file_1
private: false
meta:
action:
disabled: false
# 変数に保存
+store_value_1:
action>: StoreValue
display_name>: '変数に保存'
key: pdfText
value: +convert_p_d_f_to_text_1
setIfNotDefined: false
private: false
meta:
action:
disabled: false
# LLMによるチャット
+chat_with_l_l_m_1:
action>: ChatWithLLM
display_name>: 'LLMによるチャット'
provider_id: ''
prompt: "以下のテキストから、事業経費を半角数字で抽出してください。\n${pdfText.slice(0,500)}"
filename: ''
model: 'gpt-4o-mini'
temperature: '0'
private: false
meta:
display:
action:
disabled: false
# 変数に保存
+store_value_2:
action>: StoreValue
display_name>: '変数に保存'
key: gptResult
value: +chat_with_l_l_m_1
setIfNotDefined: true
private: false
meta:
action:
disabled: false
# LLMによるチャット
+chat_with_l_l_m_2:
action>: ChatWithLLM
display_name>: 'LLMによるチャット'
provider_id: ''
prompt: "以下のテキストを数値のみにして\n${gptResult}"
filename: ''
model: 'gpt-4o-mini'
temperature: 1
private: false
meta:
display:
action:
disabled: false
# 検索して置換_半角数字以外置換
+replace_text_1:
action>: ReplaceText
display_name>: '検索して置換_半角数字以外置換'
text: ${gptResult}
find: '\D'
use_regex: true
replace_with: ''
private: false
meta:
action:
disabled: false
ワークフローの最後に、二次元配列情報をもとにCSVファイルを作成し保存しています。
# URL上のファイルを取得_サンプルPDF
+download_file_1:
action>: DownloadFile
display_name>: 'URL上のファイルを取得_サンプルPDF'
url: 'https://support.autoro.io/wp-content/uploads/2023/05/GPT4の公示.pdf'
private: false
meta:
action:
disabled: false
# PDFからテキストを抽出
+convert_p_d_f_to_text_1:
action>: ConvertPDFToText
display_name>: 'PDFからテキストを抽出'
pdf: +download_file_1
private: false
meta:
action:
disabled: false
# 変数に保存
+store_value_1:
action>: StoreValue
display_name>: '変数に保存'
key: pdfText
value: +convert_p_d_f_to_text_1
setIfNotDefined: false
private: false
meta:
action:
disabled: false
# LLMによるチャット
+chat_with_l_l_m_1:
action>: ChatWithLLM
display_name>: 'LLMによるチャット'
provider_id: ''
prompt: "以下の文書から、[[\"勘定科目\",\"金額(数値)\"],[\"勘定科目\" : \"金額(数値)\"]] の二次元配列形式で各勘定科目を抽出して二次元配列形式で出力し、配列以外のテキストは出力しないでください。\n百、千、万、億などの漢字が入っていたら、それは対応する0の個数に置換してください。\n\n${pdfText.replace(/\\n/g,\"\")}"
filename: ''
model: 'gpt-4o-mini'
temperature: '0'
private: false
meta:
display:
action:
disabled: false
# 変数に保存_この時点ではテキスト
+store_value_2:
action>: StoreValue
display_name>: '変数に保存_この時点ではテキスト'
key: gptResult
value: +chat_with_l_l_m_1
setIfNotDefined: false
private: false
meta:
action:
disabled: false
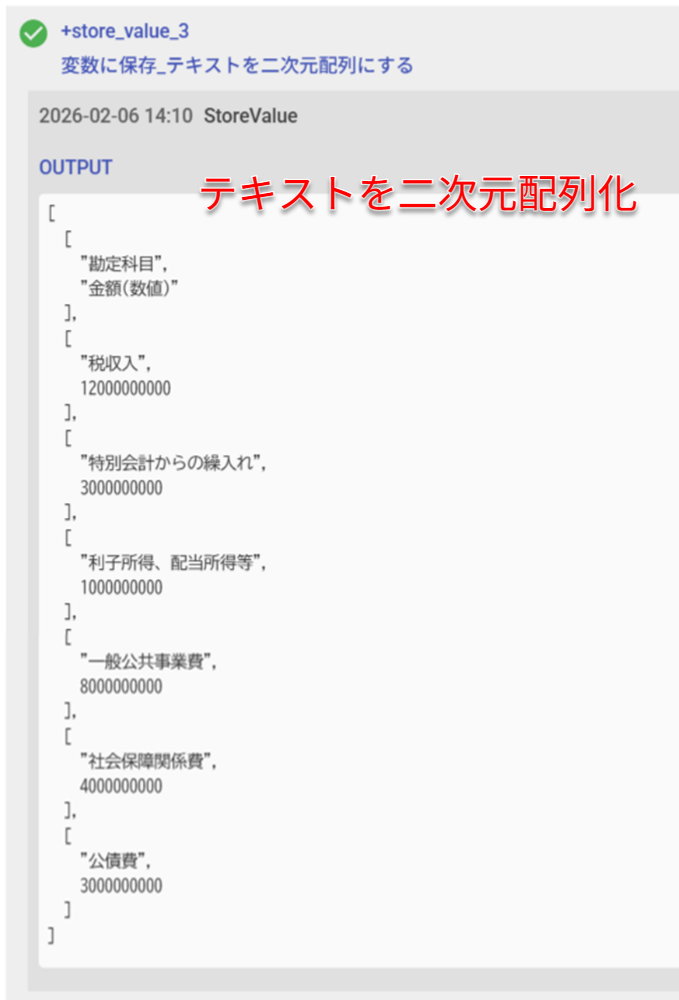
# 変数に保存_テキストを二次元配列にする
+store_value_3:
action>: StoreValue
display_name>: '変数に保存_テキストを二次元配列にする'
key: gptResultArray
value: ${JSON.parse(gptResult)}
setIfNotDefined: false
private: false
meta:
action:
disabled: false
# CSVを作成
+write_c_s_v_1:
action>: WriteCSV
display_name>: 'CSVを作成'
filename: 'gptSample.csv'
table: ${gptResultArray}
bom: true
private: false
meta:
action:
disabled: false
# ファイルを保存_AUTOROローカルストレージに保存
+save_file_1:
action>: SaveFile
display_name>: 'ファイルを保存_AUTOROローカルストレージに保存'
provider: local
filename: +write_c_s_v_1
createPath: false
private: false
meta:
action:
disabled: false
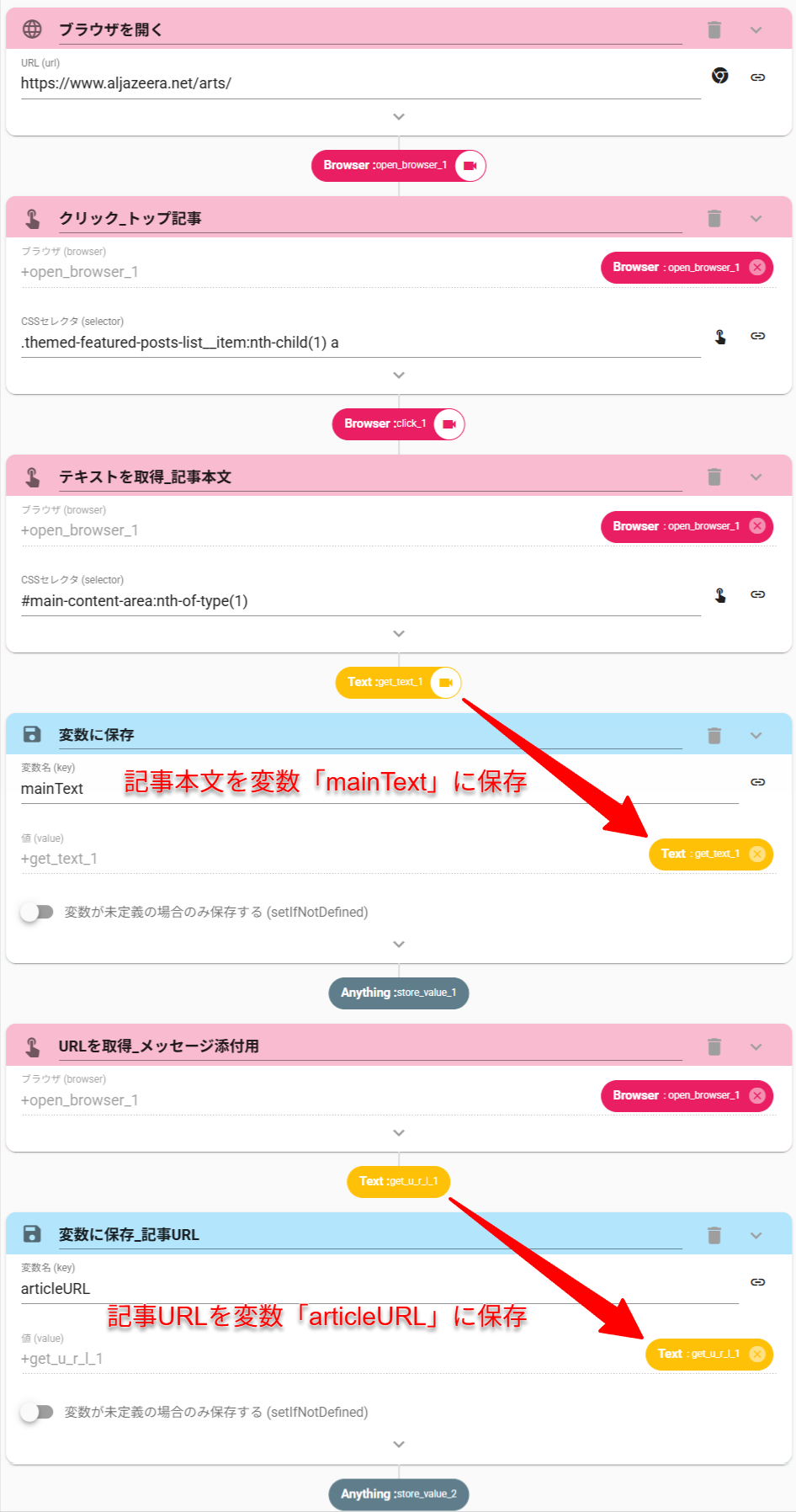
トップ記事の情報を、以下の流れで取得します。
- OpenBrowserアクション(ブラウザを開く)にて、ニュースページにアクセスする
- Clickアクション(クリック)にて、トップページ内の1番目の記事をクリックする
- GetTextアクション(テキストを取得)にて、記事内の本文テキストを取得する
- GetURLアクションにて(URLを取得)にて、記事のURLを取得する(slack本文用)
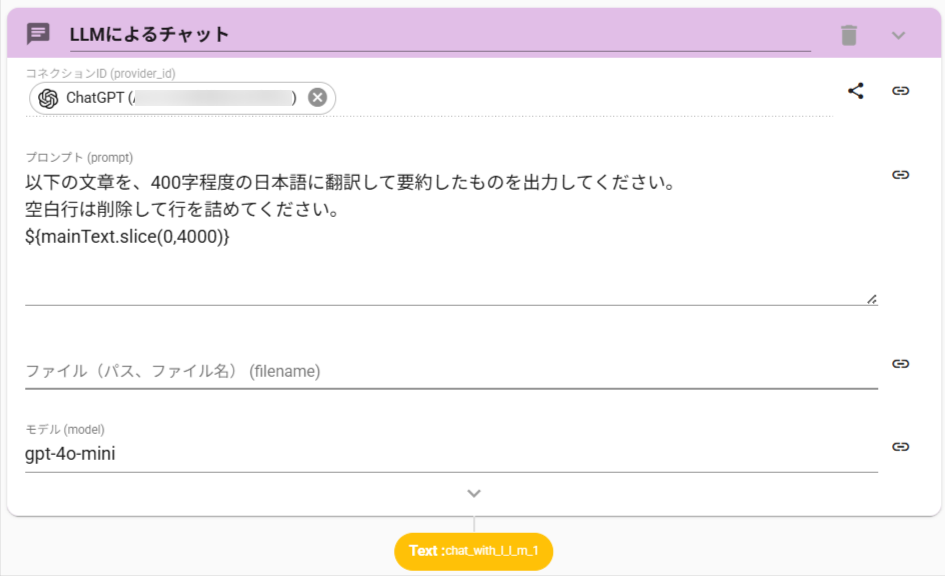
ChatWithLLMアクションをワークフロー内に設置し、今回の目的に適した命令文を作成します。
- ChatWithLLMアクションの命令文に以下を入力します。
以下の文章を、400字程度の日本語に翻訳して要約したものを出力してください。
空白行は削除して行を詰めてください。 - 「以下の文章」として、トップ記事の本文を変数化した値の、前方4000文字を与えます。(命令文が長すぎると処理できない場合があるためです)
${変数名.slice(0,4000})
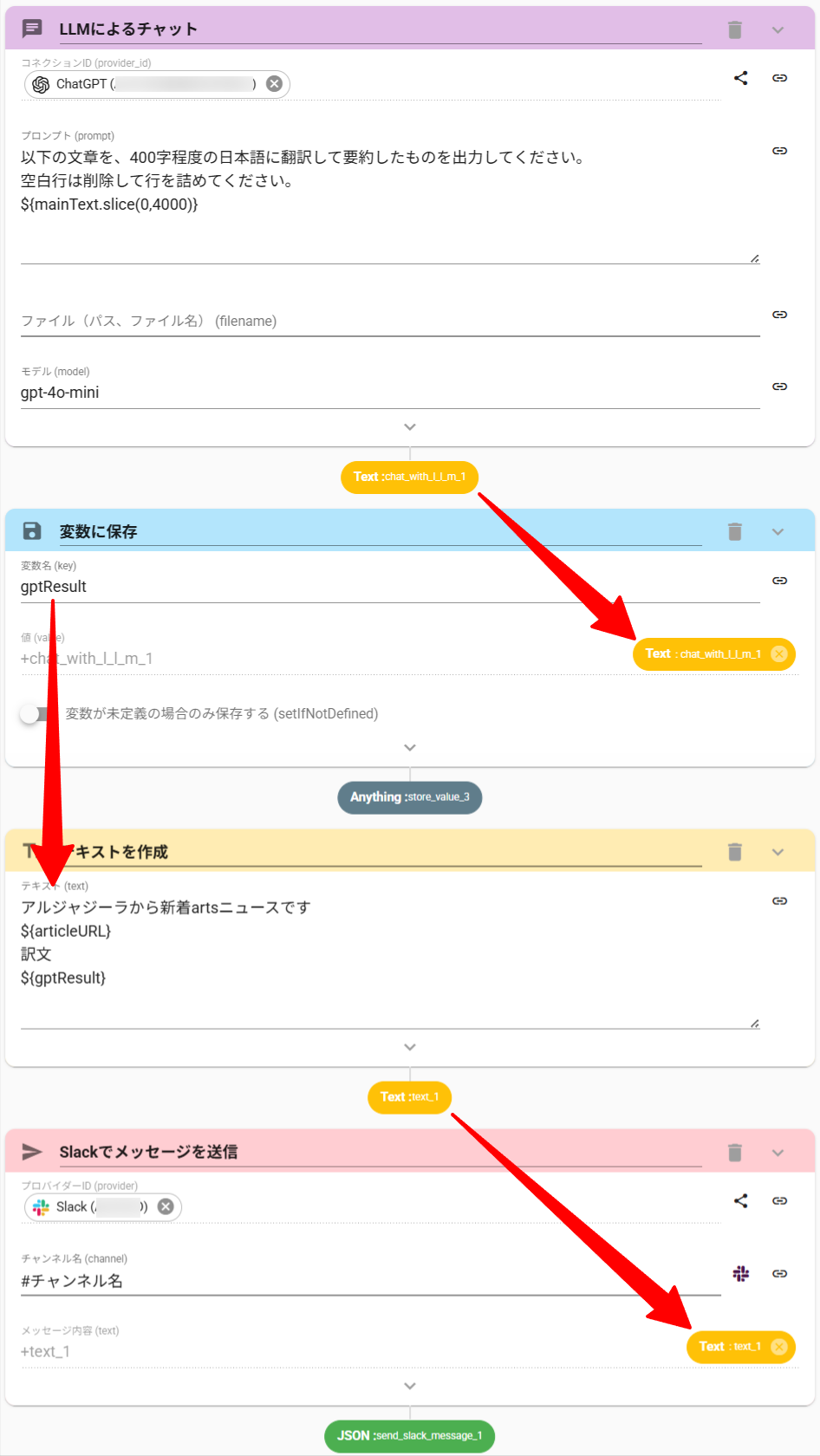
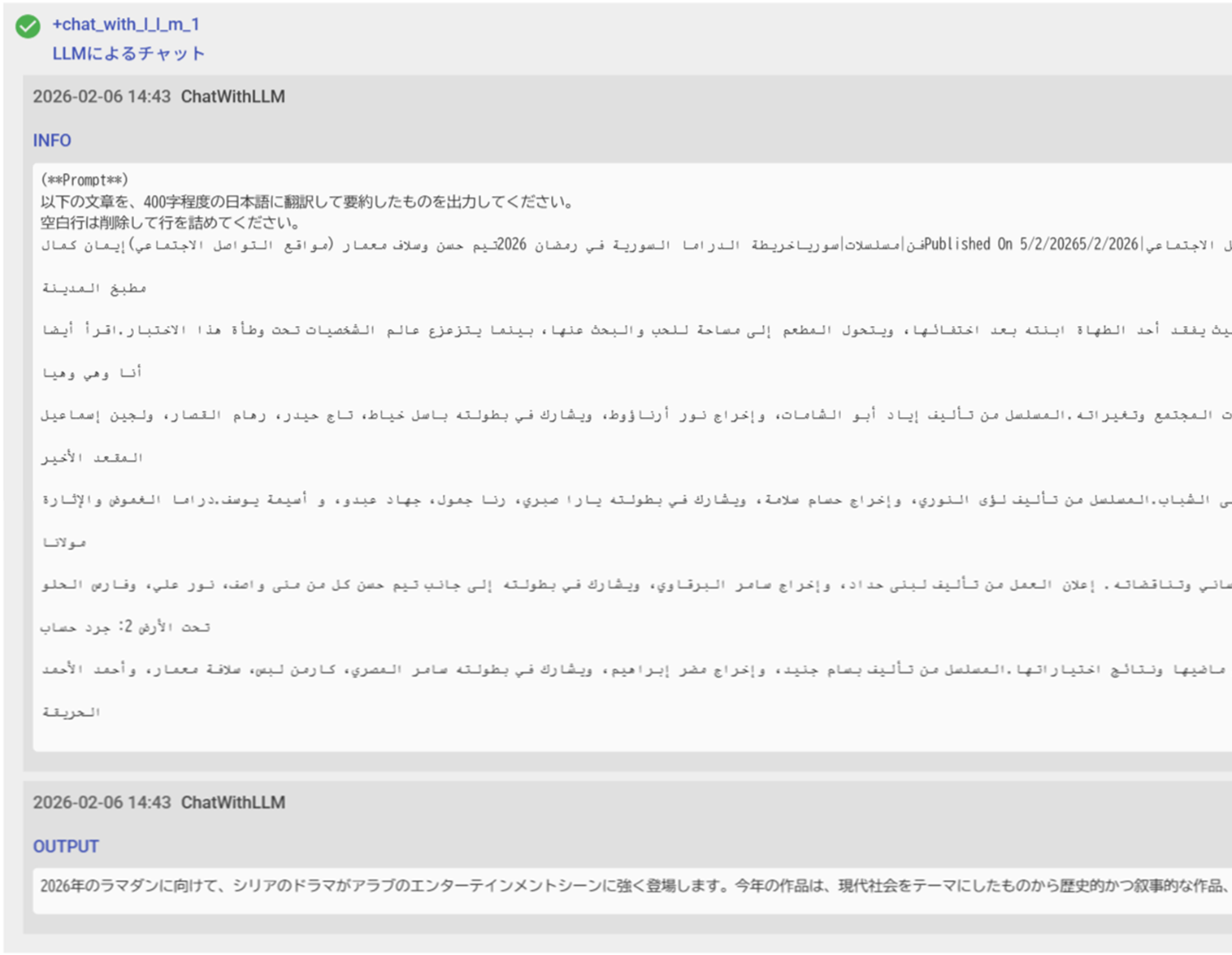

# ブラウザを開く
+open_browser_1:
action>: OpenBrowser
display_name>: 'ブラウザを開く'
url: 'https://www.aljazeera.net/arts/'
lang: 'ja-JP'
timeZone: 'Asia/Tokyo'
headless: true
confirm: true
windowSize: '1920 x 1080'
useShadowDomSelector: false
private: false
meta:
action:
disabled: false
# クリック_トップ記事
+click_1:
action>: Click
display_name>: 'クリック_トップ記事'
browser: +open_browser_1
selector: '.themed-featured-posts-list__item:nth-child(1) a'
confirm: true
waitAfter: 2000
ignoreError: true
timeout: 30000
private: false
meta:
action:
disabled: false
# テキストを取得_記事本文
+get_text_1:
action>: GetText
display_name>: 'テキストを取得_記事本文'
browser: +open_browser_1
selector: '#main-content-area:nth-of-type(1)'
ignoreError: true
private: false
meta:
action:
disabled: false
# 変数に保存
+store_value_1:
action>: StoreValue
display_name>: '変数に保存'
key: mainText
value: +get_text_1
setIfNotDefined: false
private: false
meta:
action:
disabled: false
# URLを取得_メッセージ添付用
+get_u_r_l_1:
action>: GetURL
display_name>: 'URLを取得_メッセージ添付用'
browser: +open_browser_1
private: false
meta:
action:
disabled: false
# 変数に保存
+store_value_2:
action>: StoreValue
display_name>: '変数に保存_記事URL'
key: articleURL
value: +get_u_r_l_1
setIfNotDefined: true
private: false
meta:
action:
disabled: false
# LLMによるチャット
+chat_with_l_l_m_1:
action>: ChatWithLLM
display_name>: 'LLMによるチャット'
provider_id: ''
prompt: "以下の文章を、400字程度の日本語に翻訳して要約したものを出力してください。\n空白行は削除して行を詰めてください。\n${mainText.slice(0,4000)}"
filename: ''
model: 'gpt-4o-mini'
temperature: 1
private: false
meta:
display:
action:
disabled: false
# 変数に保存
+store_value_3:
action>: StoreValue
display_name>: '変数に保存'
key: gptResult
value: +chat_with_l_l_m_1
setIfNotDefined: false
private: false
meta:
action:
disabled: false
# テキストを作成
+text_1:
action>: Text
display_name>: 'テキストを作成'
text: "アルジャジーラから新着artsニュースです\n${articleURL}\n訳文\n${gptResult}"
private: false
meta:
action:
disabled: false
# Slackでメッセージを送信
+send_slack_message_1:
action>: SendSlackMessage
display_name>: 'Slackでメッセージを送信'
provider: ''
channel: ''
text: +text_1
send_select: false
response_message: false
private: false
meta:
display:
action:
disabled: false
サイトマップとは、あるWebサイトの中にある全てのページが、どんな内容で、どこにあるのかをURLを含めて記載しているxmlファイルのことです。
これは、Googleなどの検索エンジンに気付いてもらうために設定されています。
このサイトマップをAUTOROのChatWithLLMアクションに読み込ませて適切な命令を下すと、「会社概要」「企業情報」といったページのURLを抽出できます。
さらにそのURLにアクセス後、中の文字情報を取得してChatGPTに読み込ませて適切な命令を下せば、企業の代表者名を取得することもできるようになります。
サイトマップ(sitemap.xml)の中身は、HTTPRequestアクションで取得できます。
- HTTPRequestアクション(HTTPリクエスト)を設定します
- サイトマップのURLを入力します
- リクエストメソッドにGETを指定します
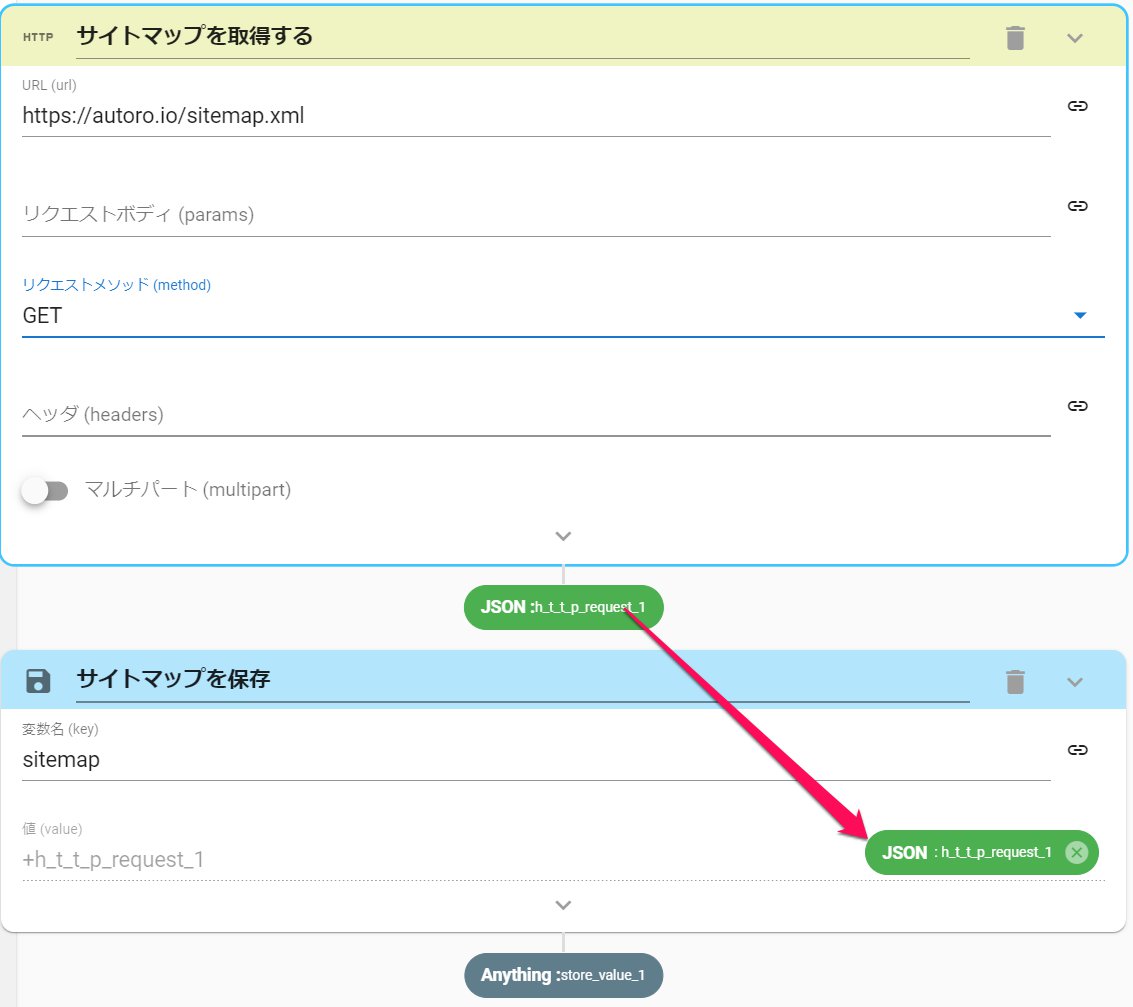
- StoreValueアクションを設定します
- 変数名を sitemap にします
- 値をHTTPRequestアクションのアウトプットにします
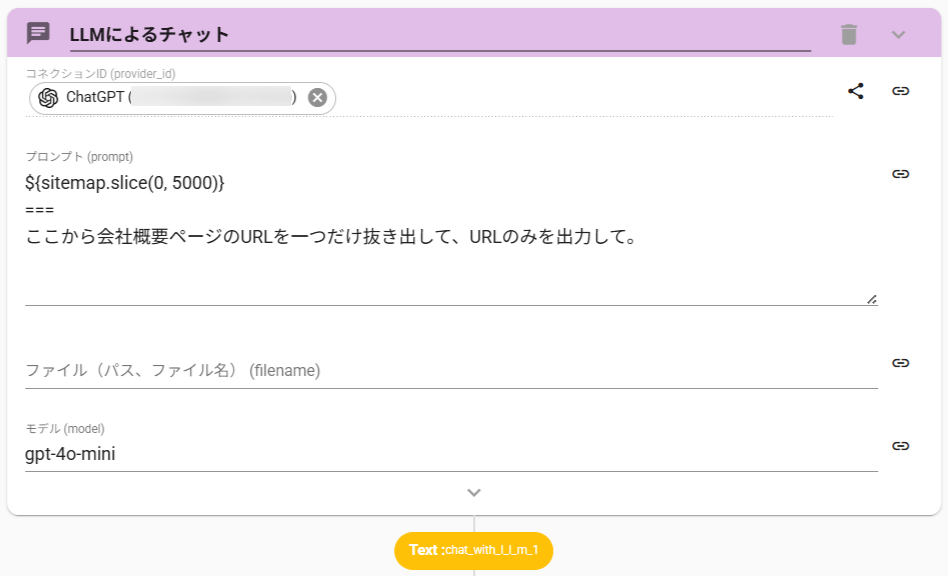
- ChatWithLLMアクションを設定します。
- 以下の命令文を打ち込みます。
${sitemap.slice(0, 5000)}
===
ここから会社概要ページのURLを一つだけ抜き出して、URLのみを出力して。
- OpenBrowserアクションを設定します
- URLに、ChatWithLLMアクションのアウトプットを指定します
- GetTextアクションを設定します
- CSSセレクタに body と入力します
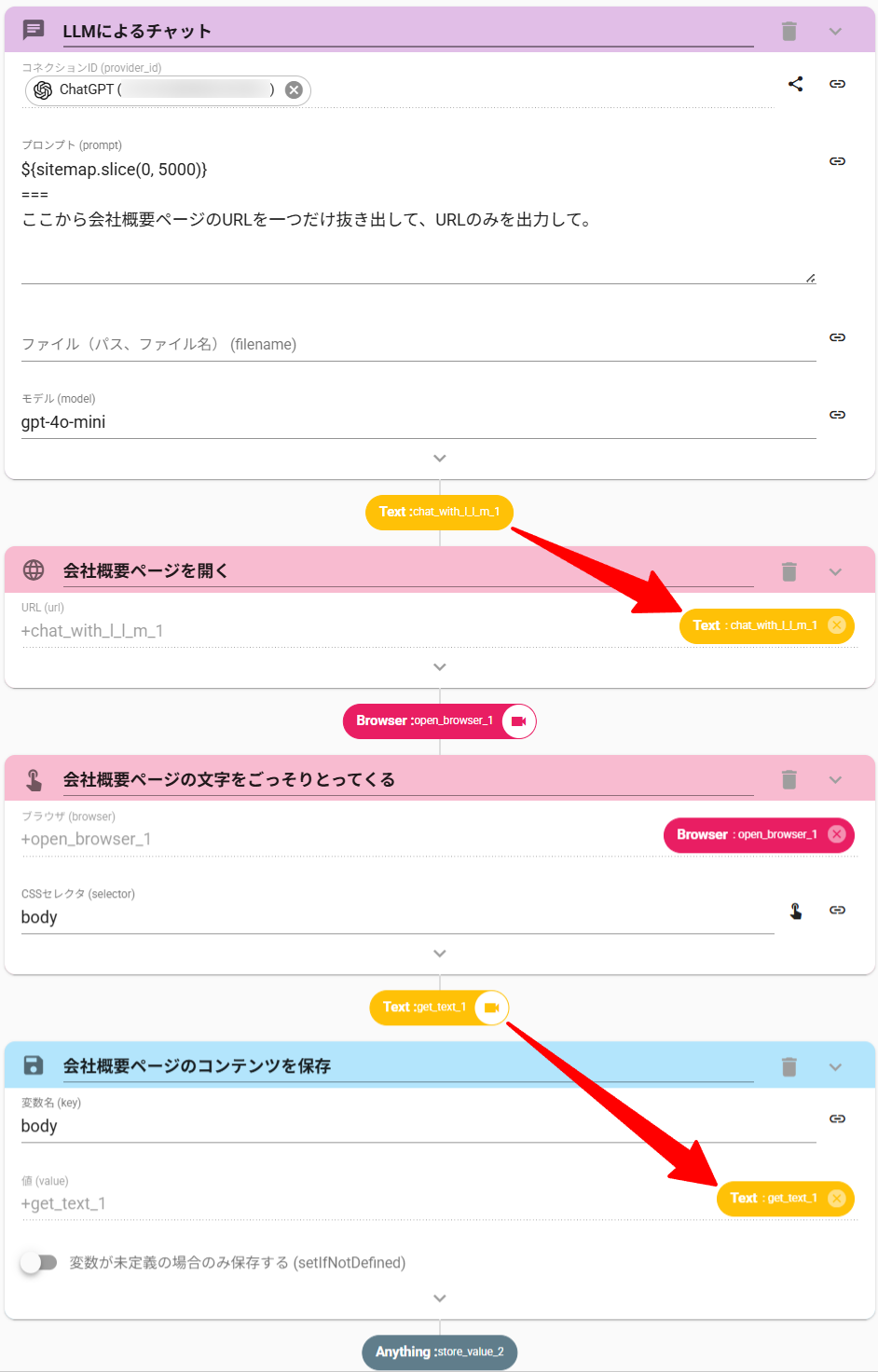
- StoreValueアクションを設定します
- 変数名を body にします
- 値をGetTextアクションのアウトプットにします
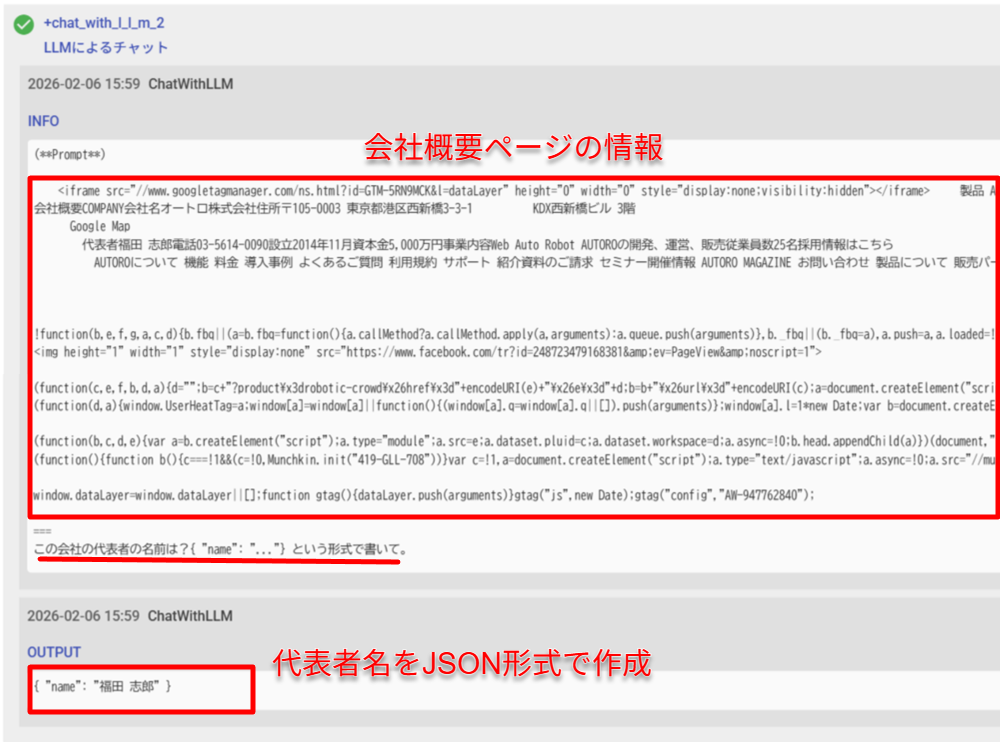
会社概要ページの本文が取得できています。あとはここから代表名を抽出してもらいましょう。
ここでは、ロボットが解釈しやすいオブジェクト(JSON)形式で抽出してもらいます。
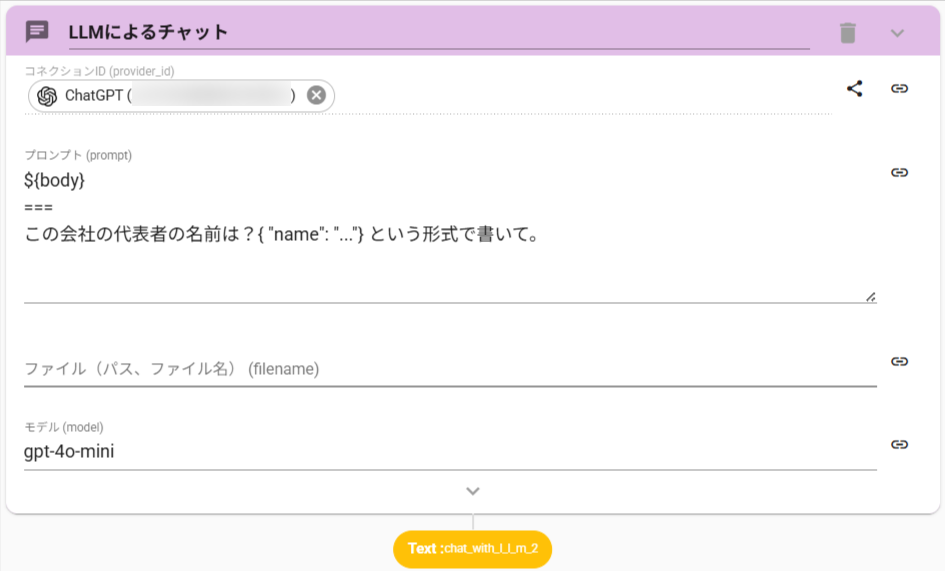
- ChatWithLLMアクションを設定します
- 以下の命令文を設定します
${body}
===
この会社の代表者の名前は?{ "name": "..."} という形式で書いて。

# サイトマップを取得する
+h_t_t_p_request_1:
action>: HTTPRequest
display_name>: 'サイトマップを取得する'
url: 'https://autoro.io/sitemap.xml'
params: ''
method: GET
headers: ''
multipart: false
private: false
meta:
action:
disabled: false
# サイトマップを保存
+store_value_1:
action>: StoreValue
display_name>: 'サイトマップを保存'
key: sitemap
value: +h_t_t_p_request_1
setIfNotDefined: false
private: false
meta:
action:
disabled: false
# LLMによるチャット
+chat_with_l_l_m_1:
action>: ChatWithLLM
display_name>: 'LLMによるチャット'
provider_id: ''
prompt: "${sitemap.slice(0, 5000)}\n===\nここから会社概要ページのURLを一つだけ抜き出して、URLのみを出力して。"
filename: ''
model: 'gpt-4o-mini'
temperature: 1
private: false
meta:
display:
action:
disabled: false
# 会社概要ページを開く
+open_browser_1:
action>: OpenBrowser
display_name>: '会社概要ページを開く'
url: +chat_with_l_l_m_1
lang: 'ja-JP'
headless: true
confirm: true
windowSize: '1920 x 1080'
useShadowDomSelector: false
private: false
meta:
action:
disabled: false
# 会社概要ページの文字をごっそりとってくる
+get_text_1:
action>: GetText
display_name>: '会社概要ページの文字をごっそりとってくる'
browser: +open_browser_1
selector: body
ignoreError: true
private: false
meta:
action:
disabled: false
# 会社概要ページのコンテンツを保存
+store_value_2:
action>: StoreValue
display_name>: '会社概要ページのコンテンツを保存'
key: body
value: +get_text_1
setIfNotDefined: false
private: false
meta:
action:
disabled: false
# LLMによるチャット
+chat_with_l_l_m_2:
action>: ChatWithLLM
display_name>: 'LLMによるチャット'
provider_id: ''
prompt: "${body}\n===\nこの会社の代表者の名前は?{ \"name\": \"...\"} という形式で書いて。"
filename: ''
model: 'gpt-4o-mini'
temperature: 1
private: false
meta:
display:
action:
disabled: false
sitemap.xmlを使わずに、トップページ内のURLから代表者名を抽出する方法の例を紹介します。
# ブラウザを開く
+open_browser_1:
action>: OpenBrowser
display_name>: 'ブラウザを開く'
url: 'https://autoro.io/'
lang: 'ja-JP'
headless: true
confirm: true
useShadowDomSelector: false
private: false
meta:
action:
disabled: false
# ページ内でJavaScriptを実行する_outerHTML, 企業URLの2列で抜き出す
+inject_script_3:
action>: InjectScript
display_name>: 'ページ内でJavaScriptを実行する_outerHTML, 企業URLの2列で抜き出す'
browser: +open_browser_1
code: "const links = [\n ...document.querySelectorAll(\"footer a\"),\n ...document.querySelectorAll(\"a\")\n]; //フッター内リンク優先\nconst arr = [];\nfor (i = 0; links.length > i; i++) {\n // arr.push(links[i].href);\n // arr.push(links[i].outerHTML);\n arr.push([links[i].outerHTML, links[i].href]);\n}\n[...new Set(arr)];\n"
returnValue: true
private: false
meta:
action:
disabled: false
# 変数に保存
+store_value_5:
action>: StoreValue
display_name>: '変数に保存'
key: links
value: +inject_script_3
setIfNotDefined: false
private: false
meta:
action:
disabled: false
# LLMによるチャット
+chat_with_l_l_m_1:
action>: ChatWithLLM
display_name>: 'LLMによるチャット'
provider_id: ''
prompt: "次のURL一覧から、会社概要ページのURLを持つ行を1つ抜き出して、2列目の値を出力しなさい。ただし、該当する行がなければ false とだけ答えなさい。\n===\n${JSON.stringify(links).slice(0,5000)}"
filename: ''
model: 'gpt-4o-mini'
temperature: 1
private: false
meta:
display:
action:
disabled: false
# 真のとき_urlがあった
+if_1:
if>:
display_name>: '真のとき_urlがあった'
condition: +chat_with_l_l_m_1
private: false
meta:
action:
disabled: false
_do:
# エラーを捕捉する
+try_1:
try>:
display_name>: 'エラーを捕捉する'
errorObjectName: isError
private: false
meta:
action:
disabled: false
_do:
# URLへ遷移
+go_to_2:
action>: GoTo
display_name>: 'URLへ遷移'
browser: +open_browser_1
url: +chat_with_l_l_m_1
private: false
meta:
action:
disabled: false
# 会社概要ページの文字をごっそりとってくる
+get_text_1:
action>: GetText
display_name>: '会社概要ページの文字をごっそりとってくる'
browser: +open_browser_1
selector: body
ignoreError: true
private: false
meta:
action:
disabled: false
# 会社概要ページのコンテンツを保存
+store_value_2:
action>: StoreValue
display_name>: '会社概要ページのコンテンツを保存'
key: body
value: +get_text_1
setIfNotDefined: false
private: false
meta:
action:
disabled: false
# LLMによるチャット
+chat_with_l_l_m_2:
action>: ChatWithLLM
display_name>: 'LLMによるチャット'
provider_id: ''
prompt: "${body}\n===\nこの会社の代表者の名前は?{ \"name\": \"...\"} という形式で書いて。"
filename: ''
model: 'gpt-4o-mini'
temperature: 1
private: false
meta:
display:
action:
disabled: false
# ブラウザを閉じる
+close_browser_1:
action>: CloseBrowser
display_name>: 'ブラウザを閉じる'
browser: +open_browser_1
private: false
meta:
action:
disabled: false
