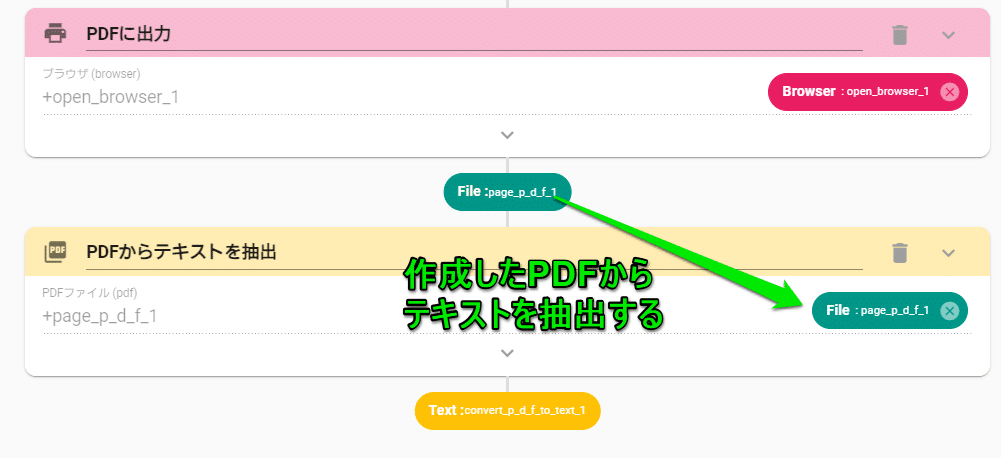
PDFファイルからテキストを抽出
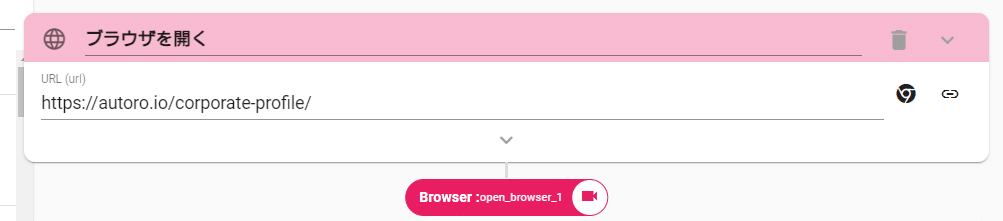

2.で作成したPDFファイルを「ConvertPDFToText」アクションに紐付けます。
※ストレージに存在するファイルを読み取る場合は、「GetFile」アクションのアウトプットを紐づければ同様の設定が可能です。
- パスワード付きのPDFは読み取ることができません。
関連して、繰り返し中に何度もPDFを読み取るフローで、パスワード付きのPDFが混じってしまいエラーになることが問題であれば、エラーを捕捉する機能をご活用ください。 - ファイル拡張子がashxになっている事実上のPDFファイルは、読み取ることが出来ます。
- 「ConvertPDFToText」アクションでは、テキストが抽出できないPDFファイルも存在します。
例:中身が画像になっているPDF/手書きのPDFなど
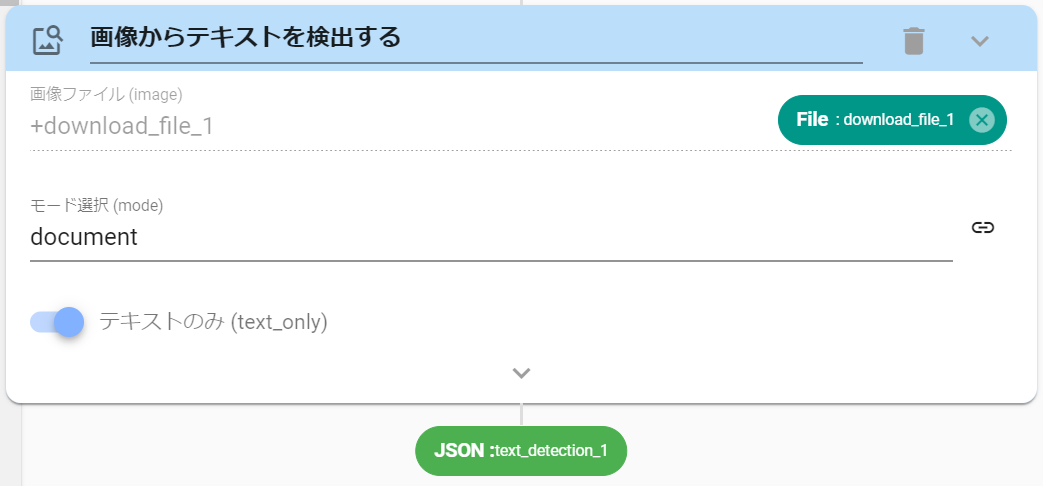
中身が画像になっているPDFからテキストを抽出したい場合は、TextDetectionアクションを使用することで文字が抽出できます(※ファイル拡張子がpdfやashxであっても中の文字が抽出できます)。
詳細は以下の記事をご参照ください。
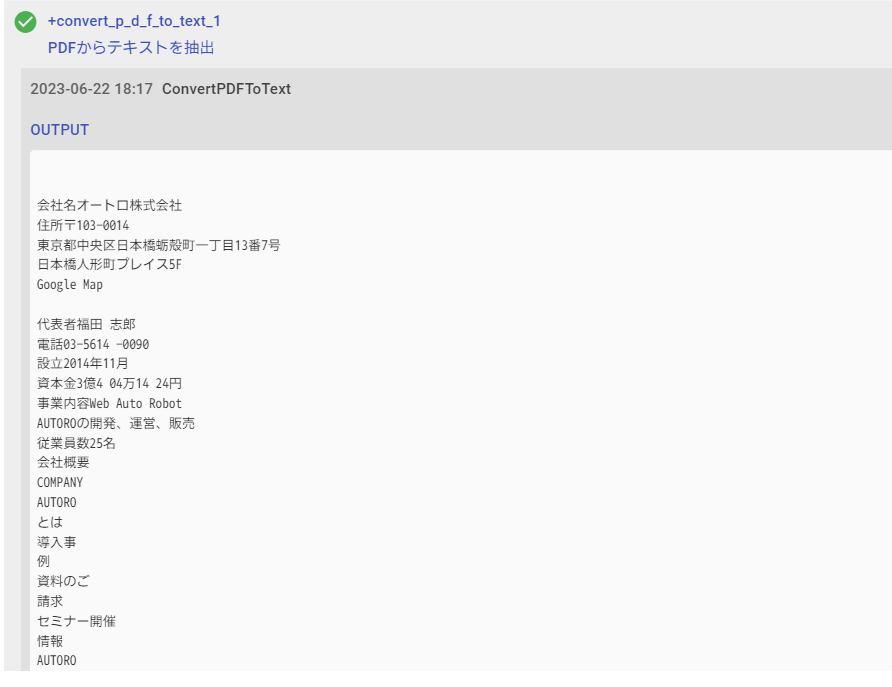
実行結果:PDF化したページが下記の様に出力されます
# ブラウザを開く +open_browser_1: action>: OpenBrowser url: 'https://docs.autoro.io/sso/onelogin' lang: 'ja-JP' headless: true useShadowDomSelector: false private: false # PDFに出力 +page_p_d_f_1: action>: PagePDF browser: +open_browser_1 format: A4 media: print printBackground: false scale: 1 private: false # PDFからテキストを抽出 +convert_p_d_f_to_text_1: action>: ConvertPDFToText pdf: +page_p_d_f_1 private: false